카프카 핵심 가이드 2E: 대규모 실시간 데이터와 스트림 처리
그웬 샤피라 , 토드 팔리노 , 라지니 시바람 , 크리트 페티 저자(글) · 이동진 번역
제이펍 · 2023년 04월 14일
1. 카프카 시작하기
어떠한 데이터를 얻을 것인지 합의하고 데이터를 얻을 수 있다면 문제는 해결된다. -닐 디그래스 타이슨
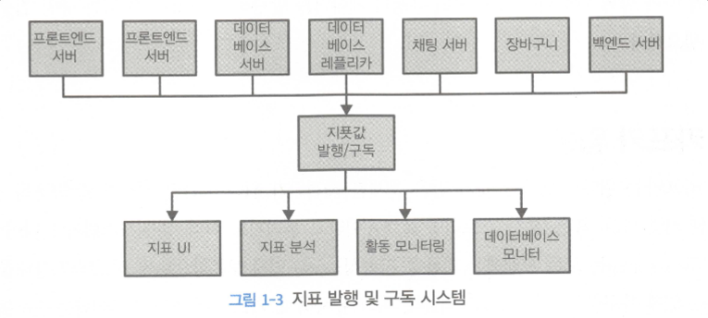
1.1 발행/구독 메시지 전달
초기 발행/구독 시스템에 비해 카프카의 장점은 발행/구독 주체들끼리 직접 연결되지 않고 `중앙 집중화된 메시지 큐 시스템`을 여러 시스템들이 공유 받을 수 있다는 점

1.2 카프카 입문
1.2.1 메시지와 배치
메시지
- 카프카 데이터의 기본 단위는 `메시지` == `레코드`
- `키` 는 메시지를 저장할 파티션을 결정하기 위해 사용한다.
배치(batch)
- 같은 토픽의 파티션에 쓰여지는 메시지의 집합
- 한 번에 하나의 메시지만 보내면 효율적이지 못하기 때문에 배치로 모아서 보냄
- 배치 크기가 커질수록 시간당 처리되는 메시지 수는 늘어나지만, 각각의 메시지가 전달되는데 걸리는 시간은 늘어난다.
1.2.2 스키마
많은 개발자들이 JSON, XML 대신 아파치 에이브로(Avro)를 선호함
- 데이터 타이핑 기능, 스키마 버전간 호환성 유지를 지원한다
1.2.3 토픽과 파티션
- 메시지의 키가 동일한 경우에 한해서, 단일 `파티션 내에서만` 메시지의 순서가 보장된다
- 서로 다른 서버들이 동일한 파티션의 복제본을 저장하도록 파티션을 복제할 수 있다. 서버 중 하나에 장애가 발생하더라도 읽기나 쓰기가 가능하다
- `스트림(stream)` : 하나의 토픽에 저장된 데이터로 간주되며 프로듀서에서 컨슈머로의 하나의 데이터의 흐름을 뜻함. 14장에서 개략적으로 다룸
1.2.4 프로듀서와 컨슈머
- 프로듀서: 메시지를 발행한다.
- 파티셔너: 메시지를 어떤 파티션에 할당할지 결정해준다. 키가 있는 경우 동일 키를 가진 메시지는 동일 파티션에 저장되는 것을 보장한다. 키가 없으면 라운드 로빈 방식으로 메시지를 파티션에 할당한다.
- 컨슈머: 메시지를 읽는다. 메시지의 `오프셋`(offset) 을 기록한다. 어떤 메시지까지 읽었는지 유지하기 위해 사용하는 지속적으로 증가하는 정수값. 메시지 저장 시 각각의 메시지에 부여하는 메타데이터이다.
- 컨슈머 그룹: 하나 이상의 컨슈머로 이루어진 집합. 각 파티션이 하나의 컨슈머에 의해서만 읽히도록 한다.

1.2.5 브로커와 클러스터
하나의 카프카 서버를 `브로커` 라 부른다. 프로듀서로부터 메시지를 전달받아 오프셋을 할당하고 디스크 저장소에 쓴다.
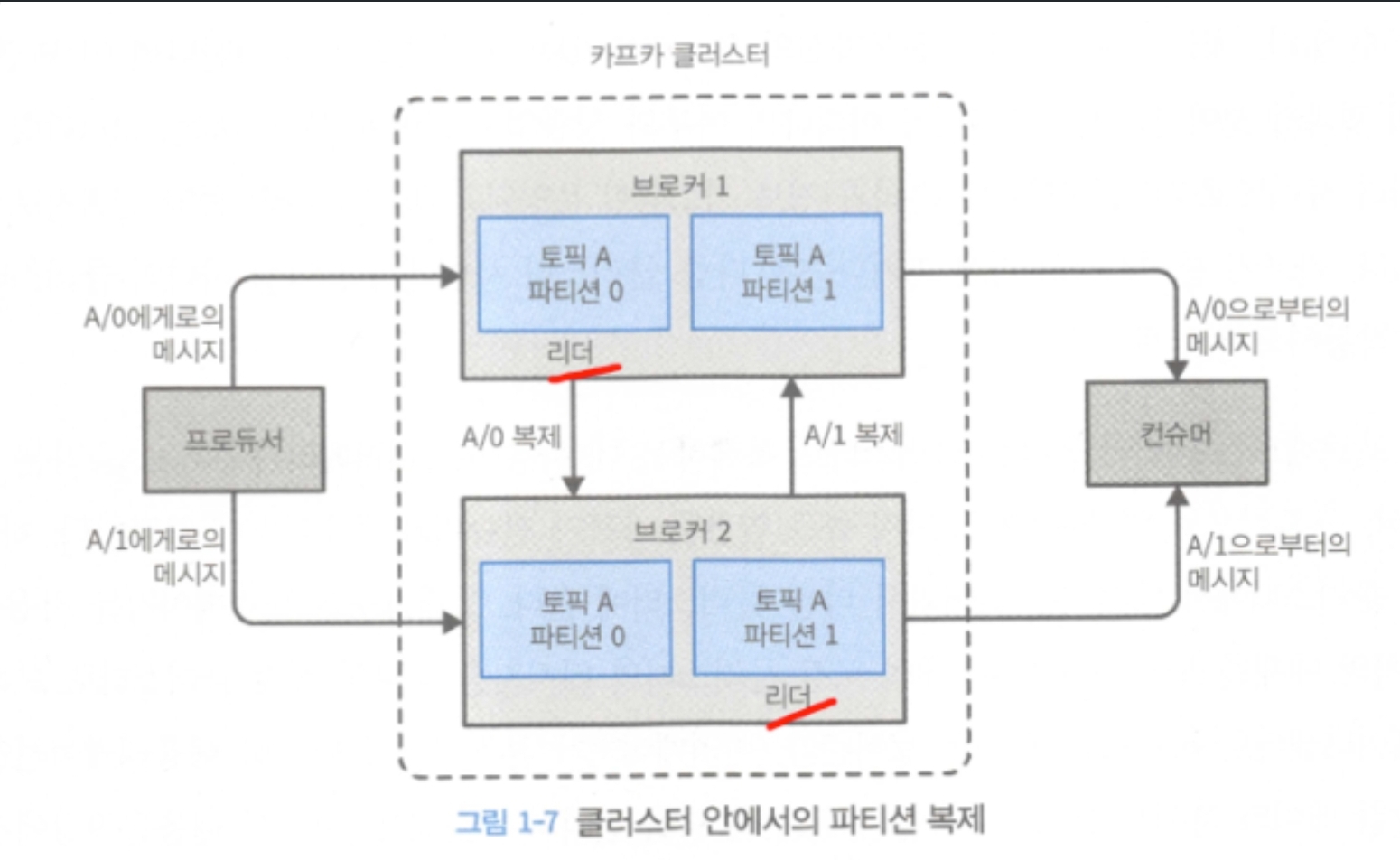
브로커도 클러스터로 구성된다. 여러 브로커에 동일 파티션을 복제해놓고, `리더 브로커`에 장애가 발생했을 때 `팔로워 브로커` 중 하나가 리더 역할을 이어받을 수 있도록 한다. 여러 개의 브로커 중 하나가 `컨트롤러` 의 역할을 하며, 컨트롤러는 파티션을 브로커에 할당해주거나 장애가 발생한 브로커를 모니터링하는 등의 관리 기능을 한다. 파티션이 여러 브로커에 복제되는 경우, 주 파티션을 `파티션 리더(partition leader)`, 나머지를 `팔로워(follower)`라고 부른다.
모든 프로듀서는 리더 브로커에 메시지를 발행해야하지만, 컨슈머는 리더나 팔로워 중 하나로부터 데이터를 읽어올 수 있다.
보존기능(retention)
디스크에 저장된 메시지를 특정 기간 동안 | 파티션의 크기가 특정 크기에 도달할 때까지 보존할 수 있다. 한도에 도달하면 메시지는 삭제된다.
`로그 압착(log compression)` 기능을 적용하면 같은 키를 갖는 메시지 중 가장 최신의 메시지만 저장된다. 최신 값 만 중요한 changelog 방식의 데이터에 로그 압착을 적용하면 좋다.
1.2.6 다중 클러스터
다수의 클러스터를 `미러 메이커` 를 이용하여 복제해놓으면 아래 이점들을 달성할 수 있다
- 데이터 유형별 분리
- 보안 요구사항 충족을 위한 격리
- 재해복구 disaster recovery, DR를 대비한 다중 데이터 센터
1.3 왜 카프카인가?
### 1.3.1 - 1.3.2 다중 프로듀서/컨슈머
토픽 기반이므로 다중 프로듀서가 메시지를 발행할 수 있고, 하나의 컨슈머가 여러 토픽에서 메시지를 읽어올 수 있다
1.3.3 디스크 기반 보존
토픽별로 보유 규칙을 다르게 지정할 수 있다
컨슈머를 정지하더라도 메시지는 카프카 안에 남아있다. 그리고 컨슈머가 다시 시작되면 작업을 멈춘 시점에서부터 유실없이 데이터를 처리할 수 있다
1.3.4 확장성
복제 팩터 등을 통해 클러스터를 유연하게 늘릴 수 있다.
### 1.3.5 - 1.3.6 고성능, 플랫폼 기능
플랫폼 기능은 개발자들이 자주하는 작업을 쉽게 수행할 수 있게 해준다는 의미이며, 대표적 라이브러리로 커넥트, 스트림즈가 있다. 각각 9장, 14장에서 다룬다
1.4 데이터 생태계
프로듀서와 컨슈머가 직접 연결될 필요가 없다는 장점에 대해 사례로 설명
1.4.1 사용 사례
1. 활동 추적: 웹사이트의 사용자 행동에 따라 대량의 데이터를 추적할 때
2. 메시지 교환: 사용자에게 이메일과 같은 알림을 보내야하는 애플리케이션에서 사용
3. 지표 및 로그 수집: 로그를 정기적으로 발송하거나, 로그 검색 전용 시스템(ex. elasticsearch), 보안 분석 애플리케이션 등으로 동일 메시지를 다양한 곳으로 발송가능
4. 커밋 로그: 데이터 베이스에 가해진 변경 사항, 체인지 로그 등을 추적하는데 사용
5. 스트림 처리: 오랜 시간에 걸쳐 누적된 데이터를 실시간으로 처리 가능
1.5 카프카의 기원
생략… 링크드인에서 사용자 추적 데이터를 생성하기 위해서 카프카를 개발했고, 개발 핵심 인원이 나와서 따로 confluent를 만듦
'Programming-[Backend] > Kafka' 카테고리의 다른 글
| [카프카 핵심가이드] 5. 카프카 어드민 (0) | 2024.11.10 |
|---|---|
| [카프카 핵심가이드] 3. 프로듀서 (2) | 2024.11.09 |
| [TIL] Kafka Transaction mode, offset lag = 1 유지 현상 (2) | 2024.09.05 |
| 카프카 멱등성(Idempotence) 설정, Retry 및 DLT 설정 시 유의사항 (2) | 2024.07.23 |
| Consumer Lag 남아있는 것 제거하기(docker kafka container shell tool 활용) (0) | 2024.07.17 |

