브로커는 중요한 부분이기도 하고, 동작원리가 꽤나 복잡한 편이라 confluent의 강의 내용으로 정리해둔다.
* https://developer.confluent.io/courses/architecture/get-started/
* https://docs.aws.amazon.com/msk/latest/developerguide/supported-kafka-versions.html#3.5.1
Inside the Apache Kafka Broker

- 카프카는 데이터와 메타데이터를 각각 관리함.
- 카프카 클러스터 내부 Control Plane과 Data Plane으로 나뉘어져있음.
- Control Plane → 클러스터의 메타데이터를 관리함
- Data Plane → 카프카에서 쓰고 읽는 실제 데이터를 처리

- 브로커의 소켓 수신 버퍼에 도착
- 네트워크 스레드 중 하나가 이를 픽업함
- 네트워크 스레드가 특정 클라이언트 요청을 픽업하면, 해당 스레드는 해당 요청 클라이언트에 대해 계속 유지됨.
- 네트워크 스레드는 소켓 버퍼에서 바이트를 가져와, 프로듀스 요청 객체를 형성하고 이를 공유 Request Queue에 넣는다.

- 카프카의 두 번째 주요 풀인 I/O 스레드에 픽업됨.
- 각 I/O 스레드는 어떤 클라이언트의 요청도 처리가 가능 (네트워크 스레드랑 달리)
- 모든 I/O 스레드는 Request queue로 들어가서 사용가능한 다음 요청을 가져옴.
- 데이터의 검증 후, 데이터를 커밋 로그에 추가해서 프로듀서 요청을 처리함.
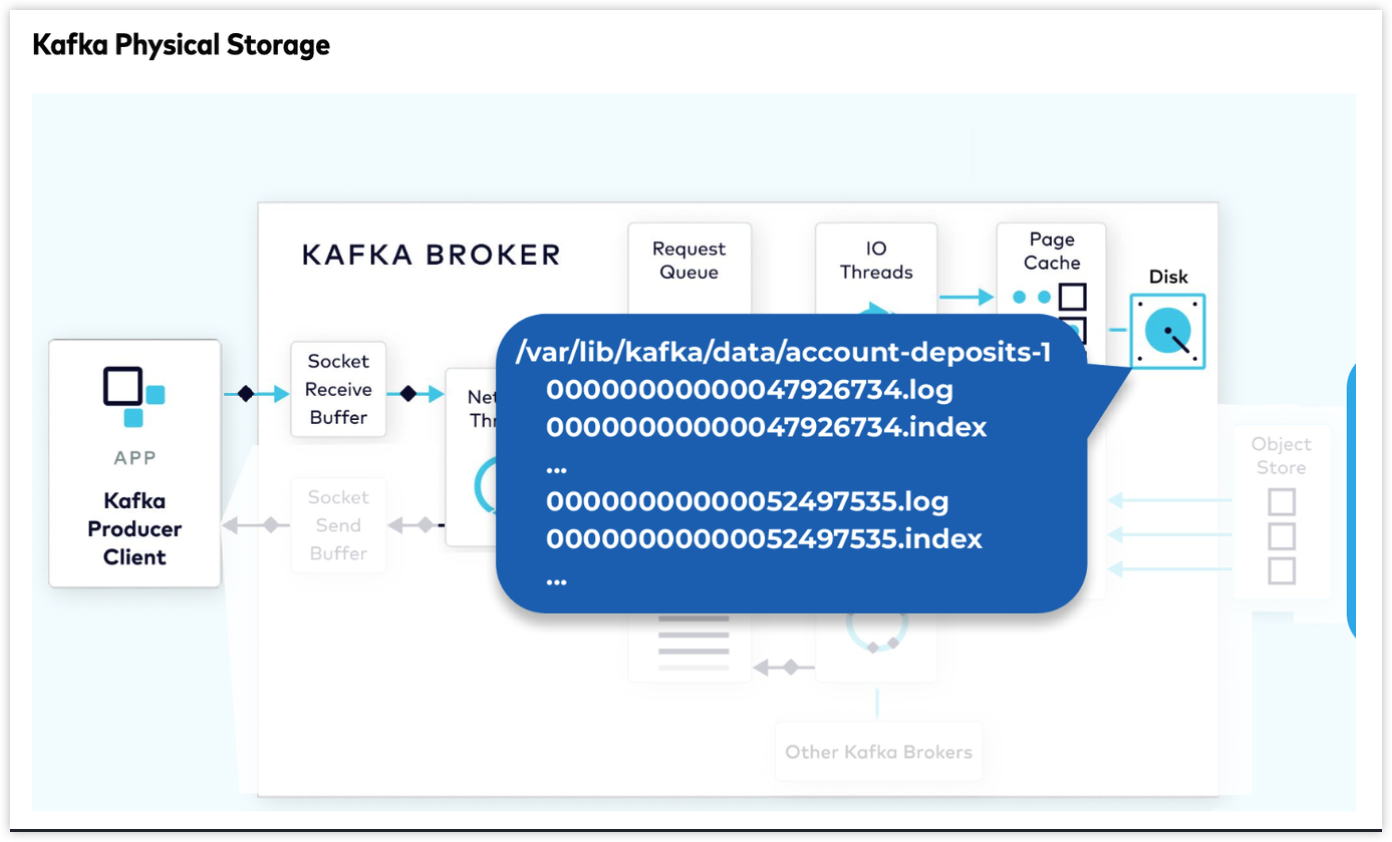
- 커밋 로그는 디스크에서 여러 세그먼트로 구성됨.
- 두 가지 주요 부분이 있는데, 하나는 실제 데이터, 두번째는 인덱스 구조로 .log 파일 내의 오프셋에서 해당 레코드의 위치랑 매핑하는 정보를 가짐

- 브로커는 데이터가 다른 브로커에 완전히 복제된 후에, 프로듀스 요청을 승인한다.
- 데이터가 완전 복제되기를 기다리는 동안 I/O 스레드를 묶어두기엔 I/O 스레드 개수가 제한적임.
- 그래서 Purgatory(Map구조) 에다가 요청을 잠시 담아둠.
- I/O 스레드는 해제되어서 다른 요청 처리하러감~

- 대기 중인 요청 데이터가 완전 복제가 끝나면, 이 프로듀스 요청은 Purgatory 에서 제거되고, 응답이 생성되어 네트워크 스레드의 해당 요청 Response Queue에 넣어짐.
- 네트워크 스레드는 생성된 응답을 픽업하고, 응답 데이터를 전송 소켓 버퍼로 보냄.
- 네트워크 스레드는 단일 클라이언트에서 오는 요청의 순서를 강제하는 역할도 함.
- 따라서, 네트워크 스레드는 한 번에 하나의 요청만 처리하고 해당 요청이 완료되고 모든 응답 바이트가 전송된 후에야, 다음 요청을 처리한다.

- 브로커의 수신 버퍼를 통해 네트워크 스레드에 픽업되고, Request Queue에 넣어진다. (프로듀서랑 동일)
- I/O 스레드에서 앞에서 언급한 오프셋 인덱스를 사용해 해당 파일(.log) 의 바이트 범위를 찾아옴.
- 새 데이터가 없는 토픽, 데이터가 충분하지 않은 경우에 해당 요청은 Purgatory에 넣어져 충분 한 데이터가 모일 때 가지 기다림.
- 데이터가 모이거나 시간이 지나면 Purgatory에서 제거되고 응답이 생성되어 Response Queue에 넣어짐.
- 네트워크 스레드는 이를 픽업해서 컨슈머 클라이언트에 전달 (zero copy transfer)
Data Plane: Replication Protocol

- 토픽을 생성할 때, replica 개수를 지정
- 해당 토픽의 모든 파티션이 지정된 replica 개수만큼 복제된다.

- 프로듀서는 리더에게 데이터를 보내고, 그 다음 모든 팔로워가 리더로부터 데이터를 가져옴
- 컨슈머는 일반적으로 리더로부터 데이터를 읽지만, 팔로워로부터 데이터를 소비하도록 구성할 수도 있음.
- ISR: 리더와 동기화된 모든 복제본을 포착한 데이터 집합

- 단조롭게 증가하는 고유 번호
- 특정 리더의 라이프 사이클을 포착하는데 사용됨.
- 리더 에포크는 모든 복제본 간의 로그 조정을 수행하는데 매우 중요한 역할을 함

- 리더가 데이터를 로컬 로그에 추가하면, 모든 팔로워가 리더로부터 새로운 데이터를 가져오려고 한다.
- 팔로워는 리더에게 데이터를 가져와야하는 오프셋을 포함한 fetch 요청을 발행해서 수행함

- 리더는 해당 오프셋의 새로운 기록을 팔로워에게 반환함.
- 팔로워가 응답을 받으면, 그 기록을 자신의 로컬 로그에 추가함.
- 팔로워가 데이터를 로컬 로그에 추가할 때, 해당 기록 배치에 포함된 동일한 Leader Epoch를 유지한다.

- 특정 레코드가 모든 동기화된 복제본에 포함되면, 해당 레코드가 커밋된다.
- 리더는 팔로워가 어디까지 복제했는지 알 수 있을까? → fetch 요청의 offset을 보고 알 수 있음.
(offset: 3 이니까, 3 전까지 모든 기록을 받았다고 알 수 있음)
- 두 개의 팔로워가 모두 offset을 3으로 요청하게 된다면, 모든 복제본이 0, 1, 2 를 받은 것이고,
0, 1, 2의 데이터는 커밋된것으로 간주함.

- HighWatermarkOffset으로 커밋을 모델링함
- 모든 기록이 커밋된 것으로 간주되는 오프셋 이전을 표시함
- Leader는 fetch 응답에 HighWatermark을 포함해서 전달
- 이는 비동기적으로 일어나기 때문에 팔로워는 HighWatermark 값이 리더보다 작을 수 있음.

- 101 브로커 리더가 장애가 생겼다고 가정
- 103을 새로운 리더로 선출함
- 이 정보는 control plane으로 전파됨.
- 103은 자신이 새로운 리더인걸 알게되면, 프로듀서로 부터 새로운 요청을 받는다.
- 이 때, 새로 증가된 Leader Epoch가 2가 된다.

- 새로운 리더가 선출되면 high watermark에 문제가 발생함.
- 새로운 리더 103의 high watermark는 이전 리더의 high watermark 보다 낮다.
- 이 시점에 새로운 Consumer가 offset 1 인 fetch 요청을 했다고 가정
- 이 때, 재시도 가능한 오류를 반환해서 high watermark가
실제 high watermark에 도달 할 때 까지 계속 재시도 하도록 한다.

- 새로운 리더 선출 후, 일부 팔로워들은 데이터를 새로운 리더와 조정해야 할 수도 있다.
- 브로커 102번은 offset 3,4 에 일부 데이터를 가지고 있지만, 이는 실제로 커밋되지 않은 기록이며
새로운 리더의 해당 기록과 상당히 다름.
- 팔로워가 fetch 요청을 발행할 때, offset 외에도 lastFetchEpoch를 포함해서 전달한다.
- 브로커 102번은 lastFetchEpoch로 1을 보낸다.

- 리더는 epoch 정보를 사용해서 로컬 로그와 일관성을 확인한다.
- 리더는 epoch 1이 브로커-102가 지시한 offset 4 대신 자신의 로그에서 offset 2에서 끝난다고 알게된다.
- 따라서, 리더는 현재 본인의 epoch 1과 일치시키기 위해 응답을 보낸다. epoch1은 endOffset 3 정보를 보냄.

- 팔로워가 fetch response를 받으면 offset 3, 4를 잘라야 함을 알게되고, offset 2 까지를 리더와 일치시킨다.
- 그리고 팔로워는 다음 fetch를 요청한다.

- 팔로워가 마지막 epoch 1, offset 3인 fetch 요청을 보낸다.
- 리더는 이를 수신하면, 로컬 로그와 일치함을 알고, 로컬 high watermark를 3으로 옮긴다.

- 리더는 새로운 데이터 응답을 반환한다.
- 팔로워는 fetch 응답을 받아서 자신의 로컬 로그에 다시 기록한다.

- 팔로워가 다시 fetch request를 날린다.
- 이제 현재 offset은 7, lastFetchEpoch는 2로 요청한다.
- 이를 보고 리더는 high watermark를 7로 옮긴다.
- 이제 리더와 팔로워의 로그 간 조정이 완료된다.

- 브로커-101이 장애가 복구되고, 102번과 유사한 조정 과정을 거쳐 로그의 끝까지 따라잡고 ISR에 추가된다.

- 팔로워가 실패할 수 있고, 또는 팔로워가 느려서 리더를 따라 잡을 수 없을 때가 있다.
- 이 경우, 해당 팔로워를 계속 기다리게 된다면, high watermark를 올릴 수 없다.
- 그래서 리더는 팔로워가 마지막으로 리더를 따라잡은 시간을 측정하고, 이 속성에 기반해서 구성된 시간보다 지연된다면, 해당 팔로워는 동기화 되지 않은 것으로 간주하고 ISR에서 제외시킨다.
- 이 시점에 리더는 줄어든 ISR set을 기반으로 high watermark를 올릴 수 있다.
The Apache Kafka Control Plane


- 클러스터의 메타데이터를 관리하는 Control Plane

- 기존의 Control Plane 관리는 주키퍼 모드로 동작
- 특별한 컨트롤러로 선택된 1개의 브로커가 존재, 이 컨트롤러는 전체 클러스의 메타데이터를 관리하고 변경
- 메타데이터는 카프카 외부에 있는 서비스인 주키퍼에서 지원된다.
- 컨트롤러는 메타데이터의 변경사항을 나머지 브로커들에게 전파하는 역할도 함.

- 새로운 Control Plane은 KRaft 라는 새로운 모듈을 통해 구현됨
- 주키퍼를 제거하고, 카프카 클러스터 내에 Raft 기반의 서비스를 구축함.
- 기존과 달리 몇몇 브로커들이 메타데이터를 관리하고 저장하기 위해 선택된다. (주키퍼는 1개)

- 카프카, 주키퍼 2개의 시스템을 관리하지 않고 1개의 카프카 서비스만 관리하면 된다.
- 일반적으로 KRaft 모델을 사용하면 클러스터 내에서 처리할 수 있는 메타데이터 양 측면에서 10배의 확장성 개선이 된다.

- 구성하는 방법은 두가지가 있다.
- 비중첩 방식으로 구성 → 일부는 브로커, 일부는 컨트롤러
- 중첩 방식으로 구성 → 일부 노드가 컨트롤러와 브로커 두 가지 역할을 모두 함

- active 컨트롤러와, 다른 컨트롤러는 각각 메모리 내에 메타데이터 캐시를 유지한다.
- active 컨트롤러가 장애나면, 나머지 컨트롤러들이 새로운 컨트롤러로 훨씬 빨리 전환 할 수 있다. (주키퍼에 비해)
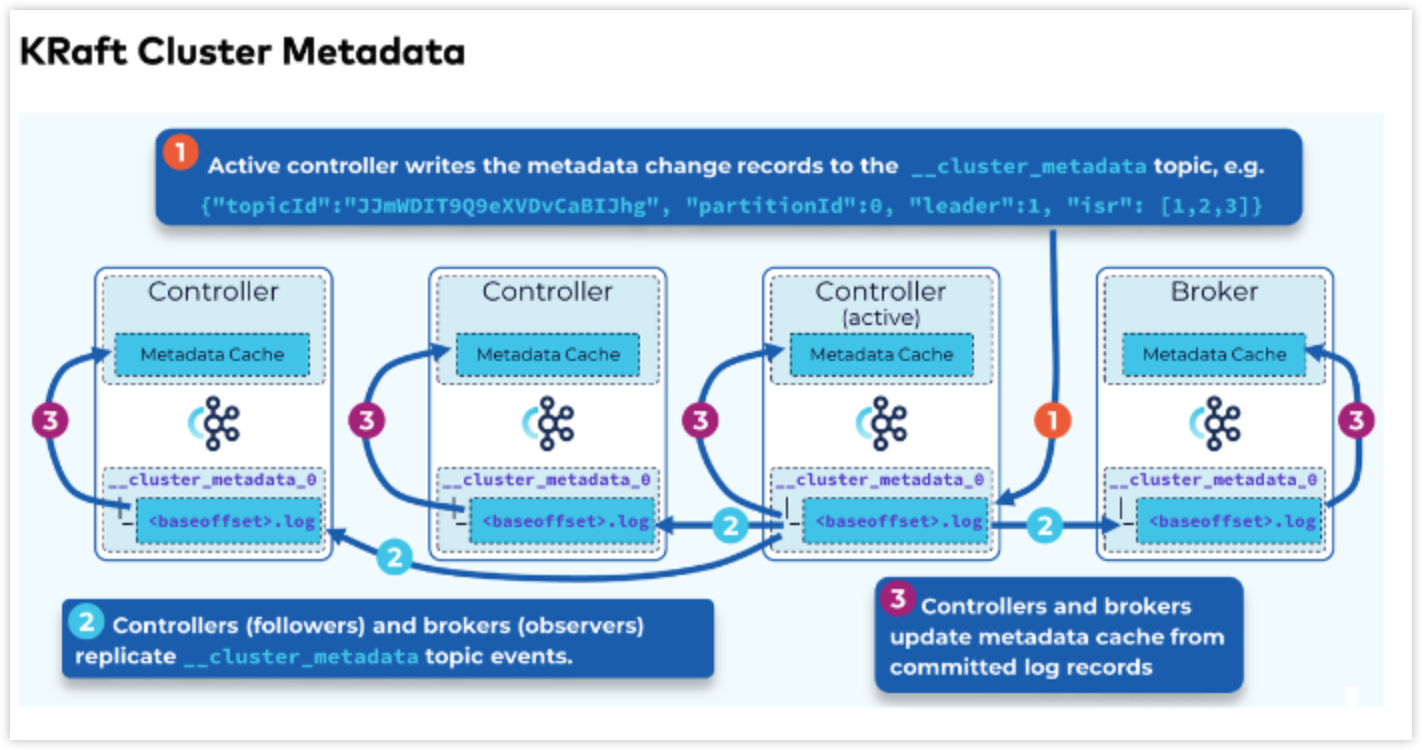
- active 컨트롤러가 특정 메타데이터를 변경하려면 __cluserter_metadata 라는 내부 토픽을 통해 저장하게 된다.
- __cluserter_metadata는 하나의 파티션만 존재하며, 모든 메타데이터를 영구적으로 저장하는데 사용됨.
- active 컨트롤러가 메타데이터를 변경하면 → 다른 컨트롤러에 복제되고, 다른 브로커들도 이 메타데이터 로그를 로컬 Metadata Cache에 복제함.

- 리더(active controller)와 팔로워라는 유사한 개념이 존재함.
- 데이터는 리더에게 먼저 전달되고 그 다음 팔로워에게 전달된다.
- Leader Epoch와 유사한 개념이 있으며 모든 기록은 로그에 추기될 때 리더 에포크로 태그된다.
- 메타데이터 복제와 데이터 복제 사이에는 몇가지 주요한 차이점이 존재
- KRaft 모드에서 리더 선출과 오프셋 커밋이 완전히 다르다.
- ISR같은 복제본 세트라는 개념이 없음.
- 따라서, 대신 리더 선출과 오프셋 커밋이 모두 쿼럼 기반 시스템에 기초한다.
- 두번째 차이점은 모든 메타데이터 기록이 로그에 영구적으로 저장되어야 한다는 것.
- 커밋되기 이전에 디스크에 플러시 되어야함.

- 컨트롤러 1의 기존 리더가 실패하여 새로운 리더를 선출해야 한다고 가정
- ISR 개념이 없기 때문에 나머지 복제본인 컨트롤러 2와 3이 새로운 리더를 선택하기 조정 필요
- 이 방식은 각 팔로워가 먼저 자신의 epoch를 증가시키고 자신을 후보로 표시한다.
- 이 특정 epoch에 대해 스스로에게 투표한다.
- 그리고 모든 다른 복제본에 투표 요청을 보내 투표를 요청한다.
- 모든 팔로워가 동시에 자신을 선출하려는 경우를 방지하기 위해 약간의 백업 논리가 존재함.
- 이 경우, 복제본 3이 처음으로 후보로 선택되었다고 가정
- 그러면 이 복제본은 자신의 후보 epoch와 로그에 대한 약간의 메타데이터를 포함하여 다른 팔로워에게 이 투표 요청을 보냄

- 먼저 이 epoch보다 높은 epoch를 본 적이 있다면 투표 반대.
- 그런 다음 이 특정 epoch에 이미 응답했다면 이전에 보낸 동일한 응답을 보낸다.
- 이 경우, 이전에 응답한 적이 없으므로 팔로워는 후보의 로그와 자신의 로그 길이를 비교.
- 후보의 로그가 동일한 epoch를 가지고 있지만 로컬 로그보다 오프셋이 더 길다고 판단 후 투표 찬성

- 후보가 충분한 표를 모으면, 완료 후 자신을 새로운 리더로 간주합니다.
- 내가 리더가 됐다! 고 알림 나를 따러라!

- 새로운 리더가 선출되면, 모든 복제본이 일관성을 유지하도록 로그 조정 과정을 거침
- 팔로워는 자신의 에포크와 오프셋을 보내는 데이터 복제 조정 논리와 유사한 과정을 거침

- 메타데이터 로그가 계속해서 커지는 것을 방지할 방법이 필요함.
- 로그의 모든 데이터를 단순하게 잘라낼 수는 없다.
- 왜냐하면 클러스터가 관리하는 일부 자원에 대한 최신값이 여전히 포함되어있을수도 있기 때문에
- 따라서, 스냅샷이라는 개념을 사용함
- 주기적으로, 각 컨트롤러와 브로커는 메타데이터 캐시의 최신 기록을 가져와 스냅샷으로 작성함.

- 스냅샷을 찍고나면 이전의 기록은 중복되어서 필요가 없어져서
- 이 시점부터 일부 오래된 데이터를 삭제할 수 있음.

- 스냅샷 사용되는 케이스
1. 브로커가 재시작될 때 마다, 이 메모리 내 메타데이터 캐시를 다시 빌드함.
2. 컨트롤러나 브로커가 리더(active controller)의 메타데이터 로그에서 메타데이터를 가져올 때 사용
- 때로 가져올 떄, 리더가 일부 최신 스냅샷을 생성 후에 앞전 스냅샷을 잘라내버려서 가져오기 요청의 오프셋이 리더의 메타데이터 로그에 더 이상 존재하지 않을 수 있다.
- 이 경우, 리더는 오프셋이 누락되었음을 알리고 스냅샷을 따라잡으라는 응답을 보냄
- 이 응답을 받은 컨트롤러나 브로커는 리더의 모든 스냅샷 데이터를 스캔하는 요청을 다시 전송해서 업데이트 함.
---
정리를 잘해주신 동료 jh님께 감사드린다.