po라는 테이블과 pol 이라는 테이블이 1:N의 관계를 갖고 있다고 가정하자.
합계 구하기

다음과 같이 조회한다면 3개의 행 값(id = 1, 2, 3)인 값이 조회될 것이다.
SELECT *
FROM po
po.id별로 조회되는 것을 확인할 수 있다.
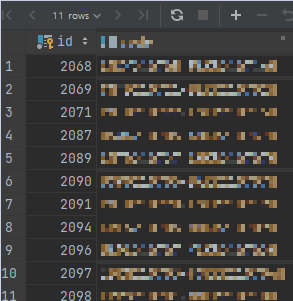
LEFT JOIN을 하면, 6개의 행 값이 조회된다.
SELECT *
FROM po
LEFT JOIN pol on po.id = pol.po_id
갯수가 더 많은 pol 기준으로 조회되고, 이에 따라 po.id가 중복된 값들을 확인할 수 있다.
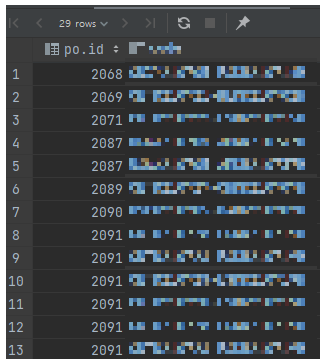
이렇게 LEFT JOIN이 된 상황에서, po.id의 갯수를 구함과 동시에 pol.id의 갯수 합계를 구하고자 하면 어떻게 해야할까? 예를 들어 위 그림에서 총 13개 행 중에 po.id가 중복되지 않는 갯수는 7개(2068, 2069, 2071, 2087, 2089, 2090, 2091) 인데, pol.id는 13개로 출력될 것이다.
집계함수와 GROUP BY
po.id별로 뭉쳐지고, pol.id의 갯수가 계산되도록 해야한다. 2087 - 2개, 2091 - 6개 방식으로 각 행이 표현된다면, po.id별로 pol.id의 갯수를 표현할 수 있을 것이다. 이때는 집계함수와 GROUP BY를 사용하면 된다.
SELECT po.id, count(pol.id)
FROM po
LEFT JOIN pol on po.id = pol.po_id
GROUP BY po.id

po.id별로 모으고 싶으니까 GROUP BY po.id로 하고, po.id로 모았을 때 1개의 po.id에 해당하는 pol.id는 여러 개 일테니, 갯수를 구하는 count 집계함수를 통해서 pol.id도 1개의 행으로 출력되도록 만들어주는 것이다.
일반화화자면, 개별적인 행으로 표현하고 싶은 항목은 GROUP BY로 나타내주고, 그에 따른 나머지 항들은 count 등의 집계함수로 뭉치는 것이라고 볼 수 있다.
만약 pol.id와 같은 단순 갯수를 count하는 부분이 아니라 총량을 합산해야되는 경우라면, 예를 들어 pol.price와 같은 금액에 대한 정보를 po.id별로 합계로 나타내고 싶다면, sum(po.price)로 표현하면 된다.
'Programming-[Backend] > SQL' 카테고리의 다른 글
| [TIL] inner join, left join의 차이. 예시 및 성능, MSSQL Server Management Studio 실행 계획 (0) | 2021.11.04 |
|---|---|
| [링크] ERD 관계선 표기법, 의미 (0) | 2021.10.19 |
| [링크][작성중] SQL Server Naming Convention (0) | 2021.09.06 |
| [TIL] SQL ANY_VALUE (0) | 2021.06.08 |
| SQL / Tutorial (0) | 2020.10.21 |

