1. 순수 JPA 페이징
JPA만 사용해서 페이징을 하는 방법은, JPQL문을 작성해서 setFirstResult, setMaxResults를 넣어주면 된다. Repository 파일에 다음과 같이 작성한다.
이미 API 상 setFirstResult, setMaxResults가 주어져서 상당히 편하다. setFirstResult는 어디부터 시작할지 결정하는, 말 그대로 offset이고, limit은 offset부터 몇개까지 결과를 반환할지를 결정한다. totalCount 메서드로 총 갯수를 구해서 구 메서드의 합계 결과를 바탕으로 Page 결과를 도출할 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public List<Member> findByPage(int age, int offset, int limit) {
return em.createQuery("select m from Member m where m.age = :age order by m.username desc")
.setParameter("age", age)
.setFirstResult(offset)
.setMaxResults(limit)
.getResultList();
}
public long totalCount(int age) {
return em.createQuery("select count(m) from Member m where m.age = :age", Long.class)
.setParameter("age", age)
.getSingleResult();
}
|
cs |
2. spring data JPA의 페이징과 정렬
Page 타입
스프링 데이터 JPA는 데이터베이스들마다 다르게 제공되는 페이징 문법을 통일된 API를 통해 자동 변환해준다. 아래와 같이 Sort, Pageable API를 사용한다.
정렬 : org.springframework.data.domain.Sort
페이징 : org.springframework.data.domain.Pageable
PageRequest 객체를 생성하고, 부모 타입인 pageable로 받도록 한다. 결과에서 .getContent()로 각 결과 객체를, .getTotalElements()로 결과의 size를 구할 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
@Test
@DisplayName("페이징 테스트")
void paging() throws Exception {
/* GIVEN */
memberRepository.save(new Member("member1", 10));
memberRepository.save(new Member("member2", 10));
memberRepository.save(new Member("member3", 10));
memberRepository.save(new Member("member4", 10));
memberRepository.save(new Member("member5", 10));
int age = 10;
PageRequest pageRequest = PageRequest.of(0, 3, Sort.by(Sort.Direction.DESC, "username"));
/* WHEN */
Page<Member> page = memberRepository.findByAge(age, pageRequest);
/* THEN */
List<Member> content = page.getContent();
long totalElements = page.getTotalElements();
for (Member member : content) {
System.out.println("member = " + member);
}
System.out.println("totalElements = " + totalElements);
}
|
cs |
<<interface>> MemberRepository
|
1
2
3
|
public interface MemberRepository extends JpaRepository<Member, Long> {
Page<Member> findByAge(int age, Pageable pageable);
|
cs |
추가로, 과거에 다른 프레임워크에서 계산을 통해서 구해야만 했던 번거로운 정보들을 메서드로 제공해준다.
.getNumber() : 현재 페이지
.getTotalPages() : 총 페이지 수
.isFirst() : 첫 페이지인지 여부
.hasNext() : 다음 페이지 존재 여부
Slice 타입
Slice 타입은 컨텐츠만 가져오고, total 쿼리는 보내지 않는다. 대신, 사용자가 지정해준 limit 숫자 대신 1개를 더 요청하는 방식으로 쿼리 중 갯수에 대한 부분이 지정되어 나간다. 이렇게 해서 hasNext 등의 다음 페이지 정보 등을 알아내게 된다.
Slice 타입은 Page 타입으로 개발 기획을 한 부분을 성능 등으로 인해 페이징 처리하지 않고 그냥 리스트로 내보내줘야하는 경우 단순히 타입 변경만으로 결과를 변환할 수 있기 위함이다. 개발을 진행하며 부딪힐 수 있는 단순 작업에 대한 리스크를 미리 최소화해주는 장치라고 할 수 있다.
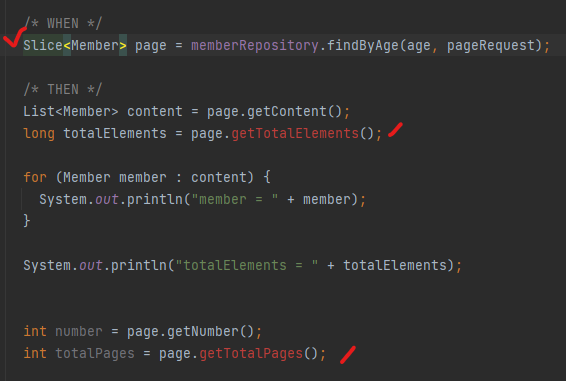
Count 쿼리
아무런 제약조건 없이 Page에 대한 쿼리를 날리면, count 쿼리도 함께 전송된다. 그런데 left join 등으로 이미 전체 레코드의 수가 메인 쿼리에서 확보된 경우에는 count 쿼리에는 join문을 포함시킬 필요가 없다. 이렇게 하면 성능이 떨어진다.
-일반 쿼리일때 : 카운트 쿼리에도 left join이 포함됨


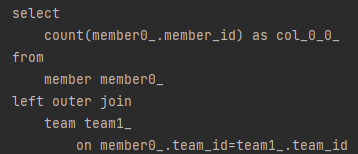
-countQuery를 따로 내보낼때 : count 쿼리에는 join문이 포함되지 않게 할 수 있다.


타입변환 : map
Page 타입으로 존재하는 엔티티를 Dto나 Rm 등으로 바로 변환할 수 있다. stream과 비슷하게 map 메서드를 이용하면 된다.

3. 벌크성 수정 쿼리(벌크 연산)
JPA는 기본적으로 단건에 대해서 쿼리를 날린다. 그런데, 만약 DB에 있는 전체 사람의 나이를 +1하는 것이 필요하다면 수 많은 쿼리를 한번에 날리는 것이 불합리할 수 있다. 그래서 한번에 데이터를 업데이트할 수 있는 방법이 제공되는데, 이것을 벌크성 수정 쿼리 또는 벌크 연산이라고 한다.
JPA 기본편에서 이미 다룬 것처럼 (https://whitepro.tistory.com/420)
createQuery문 뒤에 .executeUpadte()를 붙여주면 벌크 연산이 가능하다. 여기서는 Spring Data Jpa를 사용할때 벌크 연산을 사용하는 방법에 대해 배운다.
쿼리문은 동일하게 update문을 사용하면 되는데, @Modifying 어노테이션을 꼭 붙여줘야 한다. 이렇게 해줘야 JPA가 벌크 연산을 하는 것을 인식할 수 있게 된다. 그리고 JPA 기본편에서 다룬것과 같이 벌크 연산은 영속성 컨텍스트를 무시한채 이미 DB를 업데이트 해준 상태이고 영속성 컨텍스트는 업데이트 해주지 않은 상태가 된다. EntityManager를 사용하는 경우 em.clear를 하여 영속성 컨텍스트를 직접 초기화해줬는데, @Modifying 어노테이션으로 이 영속성 컨텍스트를 초기화해줄 수 있다. 해당 옵션이 clearAutomatically 옵션이다. default가 false 이므로 반드시 true로 옵션을 바꿔줘야 한다.
|
1
2
3
4
5
|
public interface MemberRepository extends JpaRepository<Member, Long> {
@Modifying(clearAutomatically = true)
@Query("update Member m set m.age = m.age + 1 where m.age >= :age")
int bulkAgePlus(@Param("age") int age);
|
cs |
4. @EntityGraph
EntityGraph는 fetch join을 JPQL에 적용할 때 굳이 쿼리문을 작성하지 않아도 되지 않게 해주는 어노테이션이다. JPA 기본편에서 배운 바대로, N+1 문제를 피하기 위해 Lazy fetch를 적용했다면, 연관된 객체를 한번에 들고 오기 위해서는 fetch join을 해야한다.
|
1
2
3
4
|
public interface MemberRepository extends JpaRepository<Member, Long> {
@Query("select m from Member m left join fetch m.team")
List<Member> findAllFetch();
|
cs |
그런데 spring data jpa의 기본 개념은 이렇게 쿼리문을 직접 작성하지 않는 것이므로, 이를 위해 @EntityGraph 어노테이션을 지원한다. 조인해올 엔티티의 이름만 attributePaths 속성값으로 작성해주면된다.
|
1
2
3
4
5
|
public interface MemberRepository extends JpaRepository<Member, Long> {
// @Query("select m from Member m left join fetch m.team")
@EntityGraph(attributePaths = {"team"})
List<Member> findAllFetch();
|
cs |
5. JPA Hint & Lock
JPA Hint
JPA Hint 는 SQL 힌트가 아니라 JPA 구현체 자체에서 제공하는 힌트이다. JPA에서 제공하는 것은 아니고, 하이버네이트에서 주로 제공하는 기능이다. JPA는 기본적으로 영속성 컨텍스트를 이용해서 기존 데이터를 저장해놓고, set으로 업데이트되는 데이터를 diry checking으로 감지하면서 저장하게 된다. 이는 메모리와 성능에 안좋은 영향을 미칠 수 있다.
그래서 읽기 전용으로만 사용되는데, 성능상에 이점이 많을 경우 JPA Hint를 적용할 수도 있다. 다만, 이렇게 적용해서 성능상의 이득을 많이 보긴 어렵다. 정말 핵심적으로 부하가 많이 걸리는 쿼리에 이런 힌트를 적용하면 이득을 볼 수도 있겠으나, 그런 경우는 보통 레디스 등 캐시를 이용하여 부하를 줄여주는 형태로 디자인한다. 단순히 힌트만 적용해서 성능 기준을 간편하게 맞출 수 있는 경우에만 이 기능을 사용한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
@Test
@DisplayName("")
void queryHint() throws Exception {
/* GIVEN */
Member member1 = new Member("member1", 10);
memberRepository.save(member1);
em.flush();
em.clear();
/* WHEN */
Member findMember = memberRepository.findReadOnlyByUsername("member1");
findMember.setUsername("member2");
em.flush();
/* THEN */
}
|
cs |
|
1
2
3
4
|
public interface MemberRepository extends JpaRepository<Member, Long> {
@QueryHints(value = @QueryHint(name = "org.hibernate.readOnly", value = "true"))
Member findReadOnlyByUsername(String username);
|
cs |
Lock
Lock은 DB에 동시 접근이 발생하여 트랜잭션끼리 충돌이 나는 경우 등을 방지하기 위한 기능이라고 한다. JPA에서 Lock을 적용하기 위해서는 @Lock을 사용하면 된다. LockModeType 등은 다소 깊은 내용이라 나중에 학습해보도록 하자.
쿼리문을 확인해보면 for update가 붙어서 나오는 것을 확인할 수 있다. 방언마다 다르게 작성된다고 한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
@Test
@DisplayName("")
void lock() throws Exception {
/* GIVEN */
Member member1 = new Member("member1", 10);
memberRepository.save(member1);
em.flush();
em.clear();
/* WHEN */
memberRepository.findLockByUsername("member1");
/* THEN */
}
|
cs |
|
1
2
3
4
|
public interface MemberRepository extends JpaRepository<Member, Long> {
@Lock(LockModeType.PESSIMISTIC_WRITE)
List<Member> findLockByUsername(String username);
|
cs |
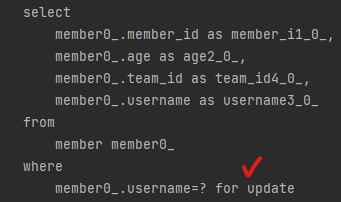
참조
1. 인프런_실전! 스프링 부트와 JPA 활용1_김영한 님 강의
'Programming-[Backend] > JPA' 카테고리의 다른 글
| [spring data JPA]4. 구현체 분석, 기타 기능 : Specification, Query by Example, Projections, Native query (0) | 2021.11.21 |
|---|---|
| [spring data JPA] 3. 확장 : Auditing, Paging - @CreatedAt, @PageableDefault 등 (0) | 2021.11.21 |
| [spring data JPA] 1. 초기 설정 및 Data Jpa 기본 (0) | 2021.11.15 |
| [JPA활용-1] 3. 도메인 개발 : Unique 제약 조건, main/test 환경 설정 분리, JPQL 동적 쿼리 등 (0) | 2021.11.10 |
| [JPA활용-1] 2. 엔티티 작성 : 계층구조 연관관계 매핑 등 (0) | 2021.11.08 |



