반정규화(De-Normalization)
반정규화는 데이터베이스의 성능 향상을 위해서 데이터 중복을 허용하고 조인을 줄이는 방법이다.
반정규화 수행 시점
- 정규화에 따라 수행 속도가 느려지는 경우*
- 다량의 범위를 자주 처리해야하는 경우
- 특정 범위의 데이터만 자주 처리하는 경우
- 요약/집계 정보가 자주 요구되는 경우
반정규화는 클러스터링, 뷰, 인덱스 튜닝, 파티션 등 대안이 있는지 확인 후에 진행한다.
*정규화를 수행하면 여러 테이블로 쪼개지고, 이에 따라 데이터를 조회할 때 조인을 사용해야한다. 조인은 단순한 코딩으로 치환하여 생각하면 이중 for문을 작성하는 것과 같다. 따라서 반정규화를하여 2개 테이블을 1개 테이블로 만들면 조인이 필요없게 되며 수행 속도의 향상이 있을 수 있다.**
**하나의 테이블에 너무 많은 컬럼이 추가되면 한 개 행의 크기가 데이터베이스 관리 시스템의 입출력 단위인 블록 크기(Block Size)를 넘어서게 된다. 이러면 1개 행을 조회하기 위해 여러 블록을 읽어야되서 성능이 문제가 될 수 있다.
※ 클러스터링(Clustering) : 인덱스 정보를 저장할 때, 물리적으로 정렬해서 저장하는 방법이다. 조회 시에 인접 블록을 연속적으로 읽을 수 있어 성능이 향상될 수 있다.
반정규화 기법
1) 계산된 컬럼 추가
통계성 정보가 자주 요구되는 경우 컬럼 내에 총 판매액, 평균 잔고 등 집계 결과값을 하나의 컬럼으로 미리 넣어놓는 방식이다. 보통 배치 프로그램 등을 이용하여 이런 정보들을 테이블에 입력한다.
2) 테이블 수직분할(참조1)
| 기본키 | 속성1 | 속성2 | 속성3 -> | 키본키 | 속성1 | + | 기본키 | 속성2 | + | 속성3 | 과 같이 수직으로 분할하는 것을 의미한다.
- 갱신 위주 분할: 데이터 갱신 시 DB lock이 걸린다. 따라서 자주 갱신이 일어나는 속성들이 있다면 이 속성들만 수직분할하는 것이 유리할 수 있다.
- 높은 조회 빈도 속성 분할: 일부 속성만 매우 자주 조회된다면, 그 속성들을 수직분할 하는게 좋을 수 있다.
- 크기가 큰 속성 분할: 이미지나 2GB 이상 저장될 수 있는 텍스트 형식 속성등을 수직분할한다.
- 보안 속성 분할: 특성 속성에만 보안 적용이 필요한 경우 수직분할하여 테이블에 보안을 적용한다.
3) 테이블 수평분할(참조1)
하나의 테이블에 있는 값을 기준으로 테이블을 분할하는 방법이다. 레코드별로 사용 빈도의 차이가 큰 경우 사용 빈도에 따라 테이블을 분할한다.

데이터 개수가 적어지므로 인덱스의 개수도 작아지고 성능이 향상될 수 있다. 다만, 만약 여러 테이블을 각각의 DB로 분할하여 저장(샤딩, Sharding)하는 경우 서버간의 연결과정 증대로 latency 발생, 1개의 서버 장애 시 데이터 무결성 유지 불가 등의 단점이 발생할 수 있다.
4) 테이블 병합
여러 테이블에서 동시에 데이터가 요청되어 조인이 많이 발생하는 경우에는 하나의 테이블로 합쳐서 사용하는 것이 성능 향상에 유리할 수 있다.
테이블 통합 시 고려사항은 다음과 같다.
- 데이터 검색은 쉽지만, 레코드 증가로 처리량이 증가한다.
- 입력, 수정, 삭제 규칙이 복잡해질 수 있다.
- Null, Default 등의 제약 조건을 설계하기 어렵다.
테이블간 1대 1, 1대 N, 슈퍼타입-서브타입 관계가 있을 수 있다. 1대 1, 슈퍼타입-서브타입 관계에서는 주로 테이블 병합이 유리하게 작용하는 부분이 클 수 있으나, 1대 N 관계의 테이블을 병합하면 많은 양의 데이터 중복이 발생할 수 있다.
파티셔닝(partitioning) - 참조2
반정규화에서의 수직, 수평 테이블 분할과 동일한 개념이다. 파티션을 사용하면 논리적으로는 하나의 테이블이지만 여러 개의 데이터 파일에 분산하여 데이터를 저장하게 된다.
- 범위 분할(Range Partition) : 데이터 값의 범위를 기준으로 분할한다. 예를 들어 우편번호를 기준으로 분할 키로 설정하여, 수평 분할할 수 있다.
- 목록 분할(List Partition) : 특정값을 기준으로 분할한다. 예를 들어 Country 컬럼이 Iceland, Norway, Finland, Denmark 중 하나에 해당되면 북유럽 국가로 파티셔닝할 수 있다.
- 해시 분할(Hash Partition) : 해시 함수를 적용하여 파티션을 수행한다. 예를 들어 4개의 파티션으로 분할할려고 한다면, 해시함수에 분할키에 해당하는 값을 넣었을 때, 0~3에 대한 해시값을 반환한다. 이후 이 해시값에 맞게 테이블을 파티셔닝하는 것이다.
- 합성 분할(Composite Partition) : 범위와 해시를 복합적으로 사용하여 분할한다. 예를 들어 범위 분할을 먼저 수행하고, 해시 분할을 할 수 있다.
분산 데이터베이스
분산 데이터베이스는 한 곳의 물리적인 데이터베이스에 데이터를 담는 것이 아니라, 여러 데이터베이스에 데이터들을 나눠놓고 논리적으로는 마치 한 곳의 데이터베이스에서 데이터를 가져다 쓰는 개념이다. 빠른 네트워크 환경이 뒷받침이 되어 데이터베이스를 분산시켜 사용성 및 성능 향상을 꾀하는 방법이다.
분산 데이터베이스 투명성
분산 데이터베이스는 6가지 투명성(Transparency)을 만족해야한다.
| 분할 투명성 | 고객은 하나의 논리적 릴레이션이 여러 단편으로 분할되어 각 단편의 사본이 여러 시스템에 저장되어있음을 인식할 필요가 없다. |
| 위치 투명성 | - 고객이 사용하려는 데이터의 저장 장소를 명시할 필요가 없다. - 고객은 데이터가 어느 위치에 있더라도 동일한 명령을 사용하여 데이터에 접근할 수 있어야 한다. |
| 지역 사상 투명성 | 지역 DBMS와 물적 데이터베이스 사이의 사상이 보장됨에 따라 각 지역 시스템 이름과 무관한 이름이 사용가능하다. |
| 중복 투명성 | 데이터베이스 객체가 여러 시스템에 중복되어 존재함에도 고객과는 무관하게 데이터의 일관성이 유지된다. |
| 장애 투명성 | 데이터베이스가 분산되어 있는 각 지역의 시스템이나 통신망에 이상이 발생해도, 데이터의 무결성은 보장된다. |
| 병행 투명성 | 여러 고객의 응용 프로그램이 동시에 분산 데이터베이스에 대한 트랜잭션을 수행하는 경우에도 결과에 이상이 없다. |
분산 데이터베이스의 장단점
참조3에 따르면 분산 데이터베이스의 장단점은 아래 표와 같다.
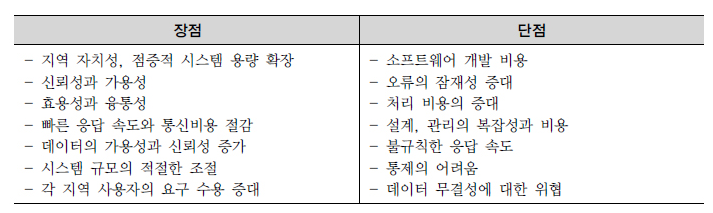
참조
0. [도서] 영진닷컴 - SQL 개발자 이론서 + 기출문제
1. 기록공간 블로그
https://lipcoder.tistory.com/337
2.블로그 - DB 파티셔닝이란
https://gmlwjd9405.github.io/2018/09/24/db-partitioning.html
3. 데이터 온에어 - 분산 데이터베이스와 성능
https://dataonair.or.kr/db-tech-reference/d-guide/sql/?mod=document&uid=336
'Programming-[Backend] > SQL' 카테고리의 다른 글
| [SQLD] 6. SQL 기본 2 - CASCADE, 테이블-컬럼 변경, 뷰(VIEW) (0) | 2022.05.14 |
|---|---|
| [SQLD] 5. SQL 기본 1 - 관계형 데이터베이스, 기본 용어, SQL 종류, 실행순서 (0) | 2022.05.14 |
| [SQLD] 3. 정규화 (0) | 2022.05.13 |
| [SQLD] 2. 엔터티, 속성, 관계, 식별자 (2) | 2022.05.10 |
| [SQLD] 1. 데이터 모델링의 종류, 특징, ERD, 3 level schema (0) | 2022.05.09 |



