이번 글에서는 애플리케이션을 업데이트하고 롤백하는 절차에 대해서 배운다. 애플리케이션이 어떤 상황에서도 잘 유지되고 업데이트 되기 위한 설정을 하는 과정이며, 교재에서 제시하는 여러 상황별로 애플리케이션의 버전을 업데이트하면서 서비스의 고가용성을 확보하는 연습을 해본다.
1. 업데이트 프로세스
기본적인 업데이트 프로세스
직접 만든 이미지를 주기적으로 업데이트해야하는 경우가 있으나, 내 이미지를 업데이트 하지않더라도 이미지가 참조하는 여러 부분들의 업데이트 때문에라도 주기적인 업데이트가 필요하다. 대표적으로 생각하고 있어야하는 업데이트 주기가 적어도 4가지가 있다.
- 애플리케이션의 의존 모듈 업데이트
- 코드를 컴파일하는 SDK 업데이트
- 애플리케이션이 동작하는 플랫폼 업데이트
- 운영체제 업데이트
각 라이브러리와 운영 체제 등에서 지속적으로 보안 업데이트 등을 하므로 적어도 한달에 한 번 이상은 업데이트가 반드시 일어나도록 되어있다. 그러므로 업데이트 및 배포에 대한 막연한 두려움을 갖지 말고 안정적이고 신뢰성있는 배포 프로세스를 만드는 것이 중요하다는 것을 인지하고 신경써야한다.
오버라이드 컴포즈 파일 병합
앞서 여러 컴포즈 파일의 중복된 부분을 하나로 뽑아내고, 환경마다 필요한 부분들만 개별 컴포즈 파일로 빼냈었다. 그리고 여러 컴포즈 파일들을 기반으로하여 이미지를 만들어냈는데, 스웜 모드의 스택 배포 시에는 단일 컴포즈 파일로 병합하여 사용해야한다.
cd ch14/exercises
docker-compose -f ./numbers/docker-compose.yml -f ./numbers/prod.yml config > stack.yml
docker stack deploy -c stack.yml numbers
docker stack services numbers
-f ..., -f ... config > stack.yml 문법으로 두 컴포즈 파일을 하나로 병합하여 새로운 컴포즈 파일을 만들어냈다.
에러 해결
위 명령어대로 실행했는데, 여러 에러들이 발생하여 수동으로 고쳐주었다.
- unsupported Compose file version: 1.0
- services.numbers-web.ports.0.published must be a integer
- (root) Additional property name is not allowed

첫 번째 에러는 컴포즈 파일의 버전이 문제인 것 같아서 병합된 컴포즈 파일에 직접 들어가서 version을 명기해주었다. 두 번째 에러는 맨 아래쪽 ports/published 부분에 "80"이라고 string으로 지정된 부분을 int로 인식하도록 쌍따옴표들을 제거해주었다. 세 번째 에러는 컴포즈 파일 내에 서비스 이름을 직접 지정하는 코드가 services: 윗 부분에 있던 것을 제거했다. name: numbers라고 되어있었는데 이 부분을 제거했다. command 상에서 numbers라고 지정하는 부분이 있기 때문에 정상 동작할 것으로 예상하였다.
version: '3.7'
services:
numbers-api:
deploy:
replicas: 6
resources:
limits:
cpus: "0.50"
memory: "78643200"
image: diamol/ch08-numbers-api
networks:
app-net: null
numbers-web:
deploy:
mode: global
resources:
limits:
cpus: "0.75"
memory: "157286400"
environment:
RngApi__Url: http://numbers-api/rng
image: diamol/ch08-numbers-web
networks:
app-net: null
ports:
- mode: host
target: 80
published: 80
networks:
app-net:
name: numbers-prod
global vs replicated

stack services 명령으로 서비스들을 조회해보면 MODE가 global인 컨테이너가 존재하는 것을 볼 수 있다. global은 한 노드에 하나의 레플리카만을 실행한다. 레플리카 하나만으로 충분한 가벼운 서비스이거나 네트워크 성능이 중요해서 인그레스 네트워크를 한 번 더 거치는 것이 부담스러운 경우에 global로 설정하기도 한다. 위 컴포즈 파일에서 보면 네트워크에서도 이 설정을 일치시키기 위해서 ports: mode: host로 지정했다.
2. v2: 업데이트 해보기, 컨테이너 자기 회복 관찰
해당 앱은 서너 차례 호출 후 이상을 일으키는 버그가 포함되어있다. 그리고 헬스 체크가 없어서 컨테이너의 상태를 체크하여 스스로 회복할 수 없다. v2로 업데이트를 해본다.
docker-compose -f ./numbers/docker-compose.yml -f ./numbers/prod.yml -f ./numbers/prod-healthcheck.yml -f ./numbers/v2.yml config > stack.yml
docker stack deploy -c stack.yml numbers
docker stack ps numbers
이번에도 오버라이드 파일을 병합 후 위에서 났던 에러를 해결한 뒤에 stack ps로 스택의 상태를 확인했다.(version 쓰기, port 정보 숫자로 고치기)

web과 api가 shutdown되고 v2 버전의 컨테이너들이 실행된 것을 볼 수 있다. 이제 리눅스인 경우 localhost:8080으로 몇 번 요청을 보내면 웹페이지가 잠시 죽었다가 다시 살아난다. docker stack ps 명령어로 확인해보면 컨테이너들이 재실행되었던 로그들을 볼 수 있다.

병합된 파일 유지
병합된 오버라이드 파일 설정으로 계속 배포를 하고 싶다면, 명령어에서 -f 를 여러 번 사용하여 업데이트마다 여러 파일들을 병합하는 것을 계속 해주어야한다. 그렇지 않으면 원래 설정대로 돌아가므로 주의해야한다.
3. v3: 롤링 업데이트 관련 설정 변경 후 배포하기
롤링 업데이트 관련 여러 속성들을 지정할 수 있다.
docker-compose -f ./numbers/docker-compose.yml -f ./numbers/prod.yml -f ./numbers/prod-healthcheck.yml -f ./numbers/prod-update-config.yml -f ./numbers/v3.yml config > stack.yml
docker stack deploy -c stack.yml numbers
docker stack ps numbers
병합된 컴포즈 파일의 일부를 발췌했다.
version: '3.7'
services:
numbers-api:
deploy:
replicas: 6
update_config:
parallelism: 3
failure_action: rollback
monitor: 1m0s
order: start-first
resources:
- parallelism: 한 번에 교체하는 레플리카의 수. 기본값은 1. 이 값이 클수록 롤링 업데이트가 빠르다.
- monitor: 다음 컨테이너 교체 전 컨테이너 이상 여부를 확인하는 시간. 기본값은 0이므로 헬스 체크 설정을 포함한 경우 이 값을 반드시 늘려야한다. 헬스 체크가 완료되기 전에 monitor가 0이라서 바로 넘어가버리면 스웜은 컨테이너가 비정상 동작을 한다고 판단할 수도 있다.
- failure_action: monitor 시간 전에 헬스 체크가 실패하거나 컨테이너가 실패한 경우 취해야하는 조치를 설정. 기본값은 업데이트 중지. 여기서는 롤백으로 설정하였다.
- order: 레플리카를 교체하는 방법을 정의. 기본은 stop-first로 이전 레플리카를 먼저 중단시키고 새로운 레플리카를 실행한다. 이렇게 하면 정의에서 지정된 레플리카의 숫자를 넘지 않는다. start-first를 하면 노드에 여유가 있는 경우 새 레플리카를 실행하여 검증 후 이전 레플리카를 제거한다.
보통 parallelism은 전체의 30% 이하, monitor는 헬스 체크 3번 정도를 기준으로 한다.
이상 업데이트, 롤백 설정 등은 아래 명령어로 확인이 가능하다.
docker service inspect --pretty numbers_numbers-api
이런 설정 값들은 롤백에도 똑같이 적용이 가능하다. 롤백 시에도 한 번에 몇 개의 레플리카를 교체할 것인지를 지정할 수 있다.
4. v5: 배포 실패 시 롤백
docker-compose -f ./numbers/docker-compose.yml -f ./numbers/prod.yml -f ./numbers/prod-healthcheck.yml -f ./numbers/prod-update-config.yml -f ./numbers/v5-bad.yml config > stack.yml
docker stack deploy -c stack.yml numbers
docker service inspect --pretty numbers_numbers-api
이 컴포즈 파일에 따른 애플리케이션은 레플리카의 업데이트가 실패하도록 설정되어있다. 그리고 롤백 설정이 되어있는데, start-first 방식으로 지정되어있다. 6개중 3개씩 교체하도록 지정했으므로 3개의 레플리카를 먼저 배포 시도하다가 실패하므로 바로 이전 버전으로 롤백하고 끝이난다. 만약 stop-first 방식을 사용했다면 3개의 레플리카를 우선 종료하므로 새로운 3개 레플리카를 띄우는 도중에는 정상 레플리카가 3개만 존재하여 처리 용량이 50%로 감소할 것이다.

위 커맨드에서는 rollback_config가 제대로 설정되지 않은 상태이다. 따라서 rollback_config 설정이 잇는 prod-rollback-config.yml 파일을 포함하여 롤백을 다시 시도해본다. 만약 아래 캡쳐대로 잘 되지 않는다면 아래 과정대로 다시 해보면 된다.
- docker stack services numbers로 레플리카 상태 확인
- docker stack rm 으로 삭제,
- 위 v3 버전의 stack을 다시 실행
- 아래 명령어로 rollback_config 설정이 포함된 명령을 실행하고, docker service inspect --pretty numbers_numbers-api를 계속 입력하면서 업데이트 상태 관찰
docker-compose -f ./numbers/docker-compose.yml -f ./numbers/prod.yml -f ./numbers/prod-healthcheck.yml -f ./numbers/prod-update-config.yml -f ./numbers/prod-rollback-config.yml -f ./numbers/v5-bad.yml config > stack.yml
docker stack deploy -c stack.yml numbers
docker service inspect --pretty numbers_numbers-api
rollback_config:
parallelism: 6
failure_action: continue
order: start-first
UpdateStatus를 보면 처음에는 updating 이였다가, 업데이트가 실패하여 rollback_started 상태가 되었다.


업데이트 중일때는 RollbackConfig의 내용이 컴포즈 파일에서 설정해준대로 적용되고 있다.

rollback_completed 상태 이후로는 RollbackConfig 설정이 기본값으로 다시 돌아간 것을 볼 수 있었다!

5. 여러 노드 중단 케이스 실험해보기
직접 가상 머신 또는 물리 머신을 갖추지 않고 여러 노드를 만들 수 있는 사이트가 있다.
https://labs.play-with-docker.com
도커 허브 계정으로 로그인 후 Add New Instance로 노드를 추가할 수 있다. 5개의 노드를 생성한 후 아래처럼 따라한다.
# node1에서
ip=$(hostname -i)
docker swarm init --advertise-addr $ip
# 명령 출력
docker swarm join-token manager
docker swarm join-token worker
# node2, node3에 manager 토큰 추가 명령
# node4, node5에 worker 토큰 추가 명령
#확인
docker node ls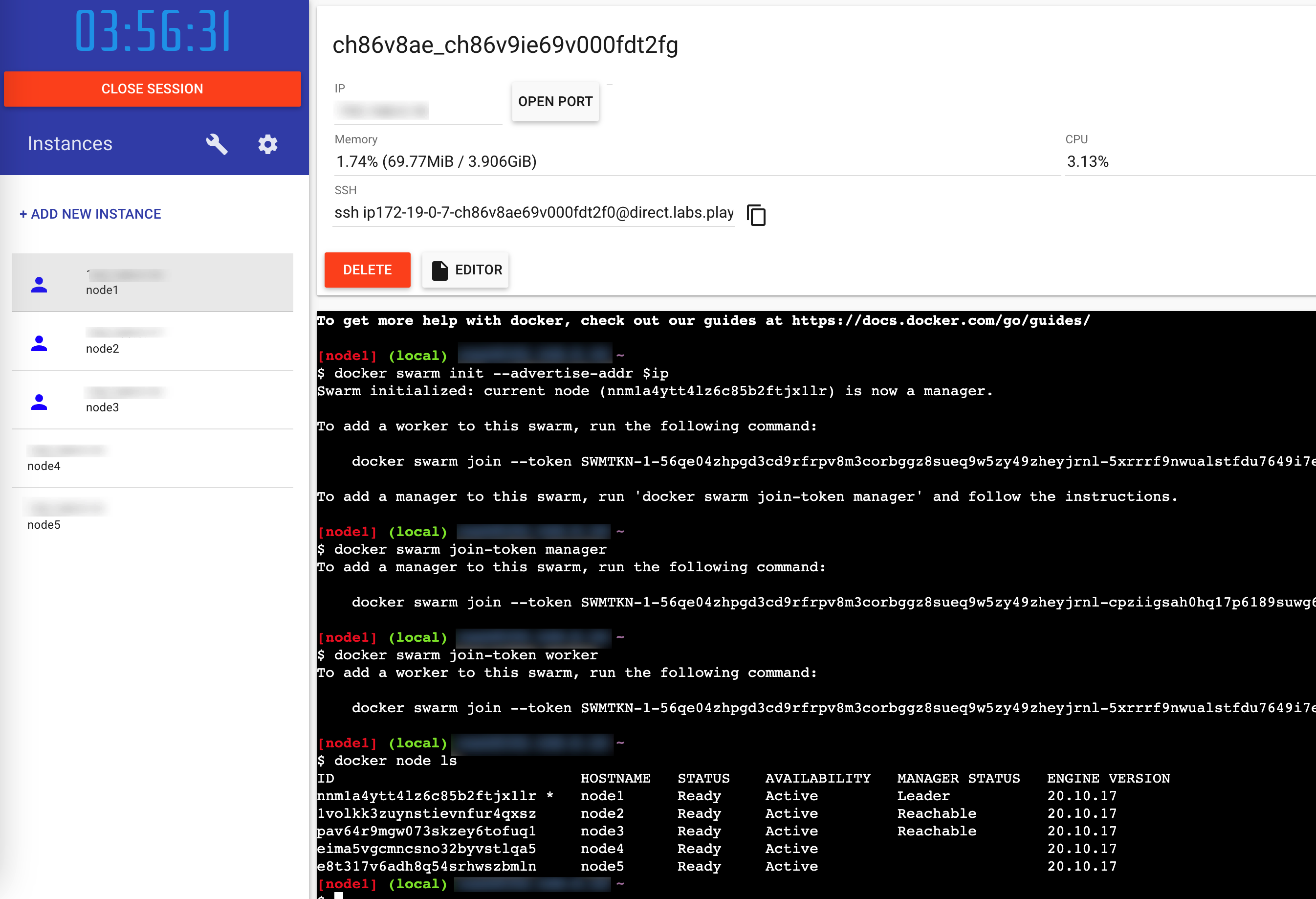
문제가 생긴 노드를 유지 보수 모드(드레인 모드, drain mode)로 전환
어떤 노드에 문제가 생겼을 때 그 노드를 드레인 모드로 전환하면 다음 재부팅 주기 전에는 이 노드에서 컨테이너를 실행하지 않을 수 있다. node1에서 아래 명령어들을 입력해본다.
docker node update --availability drain node5
docker node update --availability drain node3
docker node ls
드레인 모드가 되면 매니저나 워커 노드 모두 실행 중인 레플리카가 종료되고 새로운 레플리카를 실행하지 않는다. 그러나 매니저 노드의 드레인 모드의 경우에는 계속 클러스터의 관리 역할을 담당하며 매니저 노드 중 리더인 리더 매니저 노드가 될 수도 있다.
리더 매니저 노드가 제거되면 남은 매니저 중 1개가 리더 매니저 노드가 된다.
매니저 노드는 여러 개지만, 실질적으로 통제권을 갖는 노드는 1개로 수직적 구조를 유지한다. 이 통제권을 갖는 실질적인 리더 노드를 리더 매니저 노드라고 한다.
매니저 노드를 홀수로 유지하기 위해서 워커 노드 중 하나를 승격 해본다.
docker swarm leave --force # node1에서 입력
docker node update --availability active node5 # node2에서 입력. 드레인 모드 해제
docker node promote node5
docker node ls
매니저 노드가 홀수여야하는 이유
매니저 노드를 홀수로 유지하는 이유는 혹시라도 리더 매니저 노드가 고장이 났을 때, 해당 매니저를 포함하여 남은 매니저 노드 중 리더 매니저 노드가 될 노드를 다수결로 결정하기 때문이라고 한다. 따라서 보통 소규모 클러스터는 3개, 대규모 클러스터는 5개의 매니저 노드를 갖는다.
여러 케이스들
교재에 나온 여러 상황에 대한 설명을 기록해놓는다.
1. 모든 매니저 노드가 고장인 경우
워커 노드가 있기 때문에 레플리카들은 잘 동작하겠지만, 서비스를 모니터링 해줄 주체가 없어서 서비스 컨테이너가 고장이 나도 컨테이너가 교체되지 않는다. 매니저 노드의 복구가 필요하다.
2. 리더가 아닌 한 대의 매니저 노드만 정상인 경우
해당 매니저 노드가 리더 매니저로 승계되기 위해서 투표 및 다수결에 의한 결정이 필요한데, 1대 밖에 남지 않았으므로 이것이 불가능하다. 이를 해결하려면 남은 매니저 노드에서 swarm init 명령에 force-new-cluster 옵션을 추가하여 기존 클러스터의 데이터, 태스크를 유지하면서 강제로 해당 매니저를 리더 매니저로 만든다. 이후 매니저 노드를 추가로 투입하면 된다.
3. 노드간 레플리카 분배
서비스 레플리카는 클러스터에 노드를 추가해도 자동으로 고르게 분배되지 않는다. service update --force 명령으로 강제로 서비스를 업데이트하면 노드마다 레플리카를 고르게 배치할 수 있다.
'Programming-[Infra] > Docker' 카테고리의 다른 글
| 도커 교과서(엘튼 스톤맨, 심효섭) - 14. 도커 원격 접속, 보안과 context (0) | 2023.05.06 |
|---|---|
| [에러] 도커 교과서(엘튼 스톤맨, 심효섭) - 13. 지속적 통합(CI) 파이프라인 구축. Gogs, 젠킨스 (0) | 2023.05.05 |
| 도커 교과서(엘튼 스톤맨, 심효섭) - 11. 스택, 컨피그, 시크릿, 스웜에서의 볼륨 (0) | 2023.04.30 |
| 도커 교과서(엘튼 스톤맨, 심효섭) - 10. 도커 스웜과 쿠버네티스 소개 (0) | 2023.04.26 |
| 도커 교과서(엘튼 스톤맨, 심효섭) - 9. 여러 환경의 도커 실행 (0) | 2023.04.23 |



