1. 비트와 실수
소수는 비트로 어떻게 표현할까? 2진수를 기반으로 하기 때문에 밑을 2로 지정해야된다는 문제가 있다. 그리고 2 단위로 끊어서 표현해야되기 때문에 특정 소수는 무한대로 확장되어 정확하게 표현할 수 없다는 문제가 생긴다. 아래 예시들을 통해 이해해보자
소수점 아래 수 표기 방법
원래 정수 부분은, 예를 들어 10진수 3은 아래와 같이 표기했었다.

소수점 아래 단위는 10진수와 마찬가지로, 2진수도 지수 부분에 음수값을 넣어주면 표현이 된다. 문제1과 2의 내용을 보자.
문제 1) 10진수 0.5는 2진수로 어떻게 표시할까?
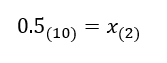
정답은 0.1이다. 실수부인 0을 0. 으로 표기해주고, 소수부인 5 부분을 아래와 같이 생각하면 된다. 그냥 쉽게 생각해보면 0.5 = 1/2 이다.

문제 2) 10진수 0.75는 2진수로 어떻게 표시할까?
10진수의 소수점 자릿수가 1개씩 늘어날때마다, 2씩 나눠주는 방식으로 2진수가 표현된다. 다시 말해 0.75 = 0.5 + 0.25(0.5 / 2)로 표시할 수 있다. 이것을 2진수로 변환하면 0.11이 된다. 아래 수식에서 2진수는 각 2진수의 상수 부분의 조합으로 0.11.... 로 표현될 것이다.

이것은 바꿔말해서, 위 수식의 양변에 2씩 곱해가면서 상수부를 표시하면 된다는 말이다.

일때, 양변에 2를 곱하면 2A = a1 + a2 x 2^-1 + ....이 된다. a1은 2진수이므로 0 또는 1이여야 한다. A 값을 알고 있다면, 2A가 1보다 큰 경우 양변에서 1을 빼줘야하므로 a1 = 1, 2A가 1보다 작다면 a1=0이 된다. 이렇게 차례대로 a1, a2...를 구하여 나열하면 소수부를 2진수로 표현할 수 있다.
이를 그림으로 표현하면 아래와 같다.
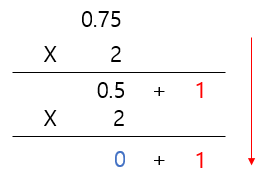
즉 10진수 0.75는 2진수로 0.11로 나타낸다.
문제 3) 10진수 0.1은 2진수로 어떻게 표시될까?
종이에 직접 위 문제2처럼 2씩 곱해가며 2진수로 적어보자. 끝이나지 않는 무한 소수가 나오는 것을 확인할 수 있다.
0.1 x 2 = 0.2 ... 0
0.2 x 2 = 0.4 ... 0
0.4 x 2 = 0.8 ... 0
0.8 x 2 = 0.6 ... 1
0.6 x 2 = 0.2 ... 1
...

따라서 컴퓨터는 2진수를 사용하기 때문에 소수점 아래 수를 완전하게 표현할 수 없다는 문제가 발생한다!
이에 따라 각종 프로그래밍 언어에서 반복문을 사용해서 0.1을 100번 더해도 10이 나오지 않는다. 9.999999998 또는 10.00000002 등 언어마다 약간 다른 값을 도출한다. 이런 문제가 있기 때문에 컴퓨터에서 소수점 아래 단위를 사용하여 연산을 할 때는 오차율을 반드시 고려하여 연산을 해야한다. 각 언어가 제공하는 float, double 등의 숫자 타입별로 소수점 7자리, 21자리 등 정확도를 보장하는 한계가 존재한다.
2. 고정 소수점과 부동 소수점에 대한 이해
위에서 10진수 소수를 2진수로 표현하는 방법에 대해서 알아봤다. 이제 비트로 표현되는 이 값들을 어떻게 메모리에 저장할 지 그 방법에 대해 이야기해본다.
고정 소수점(fixed point)
컴퓨터는 비트 단위로만 연산되고, 저장공간에 한계가 있기 때문에 정의된 공간 속에서 특정 위치에 소수점을 찍어 비트를 나누는 방법을 사용할 수 있다. 4비트의 공간을 사용하는 경우, 소수점을 중간에 고정하여 아래와 같이 표현할 수 있을 것이다. 이렇게 하면 0부터 3.75까지 0.25 단위로 표기할 수 있다.

고정 소수점을 사용하는 경우 실제 세상에서 사용하는 수를 표현하는데 너무 많은 비트가 소모된다. 예를 들어 플랑크 상수는 6.63 x 10^-34 J/s, 아보가드로 수는 6.02 x 10^23 /몰 이라는 단위를 갖는다. 두 수간의 범위는 10^57 정도이며 2진수로 환산하면 대략 2^191 정도가 된다. 거의 200비트가 필요하므로 수를 표현하는데 너무 많은 비트가 필요한 문제가 발생한다. 이런 문제를 해결하기 위해서 부동 소수점 개념을 적용한다.
부동 소수점(float point)
아닐 부, 움직일 동이 아니라, 물에 둥둥 떠다닌다는 의미의 부동 소수점이다. 소수점의 위치가 움직일 수 있다는 측면에서 부동 소수점이라고 부른다. 부동 소수점은 과학적 표기법(scientific notation)을 사용한다. 과학적 표기법에서는 10진 소수점 왼쪽이 한 자리까지만 오도록하고 이를 가수(mantissa)라 한다. 그리고 10을 몇 번 곱하는지를 표기하는데 이를 지수(exponent)라고 한다. 예를 들어 0.0012 는 1.2 x 10^(-3)으로 표기할 수 있으며 여기서 1.2를 가수, -3을 지수라고 표현한다.
1.2 x 10^(0) = 1.2 이면 소수점 왼쪽의 자리 수가 1의 자리가 된다. 1.2 x 10^5 = 120,000 라면 소수점 왼쪽의 자리 수가 100,000이 된다. 과학적 표기법으로 1.2만 보자면 마치 소수점이 고정된 것처럼 보이나, 지수부분이 어떤가에 따라서 소수점의 위치가 달라지게 되어 부동소수점으로 부르는 것이다.

한계점
이 방식은 비트가 낭비된다는 한계점이 있다. 위 표만 봐도 0을 표기하는 방법이 4가지나 된다. 또한 수를 표현하는 경우의 수가 한정적이라는 단점이 있다. 예를 들어 0.5(0.100)을 2개 더해서 1.0(1.000)으로 표기할 수는 있지만, 0.5(0.100)과 2.0(0.110)을 더해서 2.5를 비트로 표현할 패턴이 존재하지 않는다.
3. IEEE 754 부동소수점 표준과 2의 보수
현재 컴퓨터에서 실수를 표현하는 표준은 IEEE(전기 전자 기술자 협회) 에서 개발한 표준 부동소수점 방식이다. 보통 32비트의 수를 표현할 때, 아래와 같이 표현한다.

32비트를 단정도라 하고, 배정도(double precision) 표현에서는 64비트(8바이트)를 사용한다.
예시
-314.625를 IEEE 754 부동소수점 방식으로 표현해보자.
부호
부호가 음수이므로 가장 앞자리는 1이 된다.
가수부
314.625는 2진수로 변환하면 100111010.101_(2)가 된다. 소수점을 옮겨서 한자리만 남도록 정규화하면, 8번 옮기므로 지수부는 8이 된다.

정해진 23비트 중, 앞에서부터 채워주며, 뒤쪽 남은 비트는 0으로 채워준다.

지수부 : 2의 보수 방식 적용
지수는 8인데, 여기에 127을 더해주는 방식을 2의 보수 방식(bias) 이라고 한다. 2의 보수는 음수도 표현하기 위해서 아래와 같은 방식으로 지수부를 표현하는 것이다.

bias 자체가 127이며, 8 + 127 = 135를 2진수로 변환하여 지수부에 채워주면 된다.

4. 텍스트 표현
텍스트 표현에서 중요한 부분은 아스키 코드, 유니코드, UTF-8 정도일 것이다.
아스키 코드 (ASCII Code)
아스키 코드는 키보드에 있는 모든 기호에 대해 7비트 수를 할당한 것이다. 다만 컴퓨터는 8비트 단위로 처리하는 것이 쉽기 때문에 8비트로 각 문자를 표현한다. 아스키 코드 표는 인터넷에서 쉽게 찾아볼 수 있다. 일반적인 문자 외에 NUL과 같은 코드를 제어문자라고 하며 글자를 출력하는데 사용되는 것이 아니라 장치를 제어하는데 사용된다.

유니코드, UTF-8
국제화가 진행됨에 따라 각 국의 언어들을 7비트 또는 8비트 내에서 처리하는 표준을 만들기 시작했다. 이후 장비가 발달함에 따라 16비트 기반의 유니코드가 표준으로 지정되었다. 그 후 유니코드는 더 많은 문자를 담기 위해서 21비트까지 확장되었다.
나라 언어별 유니코드 매핑표 : https://ko.wikipedia.org/wiki/%EC%9C%A0%EB%8B%88%EC%BD%94%EB%93%9C_%EC%98%81%EC%97%AD
UTF-8은 이렇게 정의된 유니코드를 어떻게 컴퓨터가 인식할 수 있는 2진수로 인코딩(encoding)할 것인지에 대한 약속이다. 이렇게 인코딩할 때 기본적인 규칙은 해당 글자의 바이트마다 접두 문자를 다르게 한다는 것이다. 'a'는 1바이트이고, '가'는 3바이트로 표현된다. 인코딩할 때 2 바이트는 110, 3바이트는 1110으로 시작하고 나머지는 10으로 시작하기로 규칙을 정했다. 따라서 '가'에 해당하는 유니코드를 UTF-8으로 인코딩하면 1110으로 시작하는 어떤 2진수가 될 것이다.

참조
0. [책] 한 권으로 읽는 컴퓨터 구조와 프로그래밍
1. 지수 계산
https://blog.naver.com/falcon2026/221375986560
2. 부동 소수점에 대한 이해
https://thrillfighter.tistory.com/349
https://codetorial.net/articles/floating_point.html
3. Unicode와 UTF-8 간단히 이해하기
'Computer Science > Introduction' 카테고리의 다른 글
| 4. 비트처리 하드웨어 : 릴레이, 진공관, 트랜지스터, 논리게이트 (0) | 2022.04.10 |
|---|---|
| 3. 디지털 게인과 증폭 회로: gain, distortion, threshold, cutoff, saturation (0) | 2022.04.10 |
| 1. 컴퓨터 내부의 언어 체계 - 비트와 논리연산, 정수 (0) | 2021.07.09 |
| 2. 컴퓨터의 정보 표현 (0) | 2020.06.30 |
| 1. Hardware (0) | 2020.06.28 |



