7. CloudFront
CloudFront의 개념과 특징
CloudFront는 S3 버킷의 파일을 이용하여 정적이거나 동적인 웹사이트를 운영하는데 사용되는 콘텐츠 전송 네트워크(Content Delivery Network, CDN) 웹 서비스이다. 앞서 S3만 이용하면 HTML, CSS 등을 기반으로 정적 웹사이트를 운영할 수 있다고 배웠으나, CloudFront를 사용하면 동적인 웹사이트 호스팅도 가능해진다. 또한 여기서 CDN은 보통 웹 페이지에 대한 요청을 분산 처리해주는 분산 네트워크 시스템(Distributed Network System)을 뜻한다.
- 오리진(Origin): 최초로 웹사이트가 호스팅 되는 곳
- 엣지 로케이션(Edge Location): 오리진에서 웹사이트의 데이터를 받아서 컨텐츠의 원본을 캐시로 저장하고 있는 곳. AWS 메인 데이터 센터라고 불리며 전 세계의 지역에 존재한다. CloudFront에 웹사이트의 서버가 호스팅 되면서 사용자의 요청을 받으면 사용자가 위치한 가장 가까운 엣지 로케이션을 참조하여 컨텐츠가 전달된다. 이에 따라 지연 시간(latency)이 줄어든다.
분산 처리되므로 지연시간이 줄어듦에 더해서, CloudFront를 사용하면 컨텐츠마다 '컨텐츠 프라이버시'를 설정하므로 보안이 향상된다. 그리고 데이터를 전송할 때만 비용이 청구되기 때문에 웹사이트 호스팅의 비용이 한층 더 저렴하다.
실습
s3 버킷을 '북부 버지니아'로 생성해본다(거주 지역이 한국이기 때문에). 다른 지역에서도 접근할 수 있도록 [모든 퍼블릭 액세스 차단] 옵션은 해제한다. 그리고 버킷에 아무 이미지 파일을 하나 올린다. 나의 경우 7.6MB의 이미지 파일을 올리는데, 약 3초 정도가 걸렸다. 다른 지역에 있는 버킷이므로 속도 지연이 포함된 시간이다.
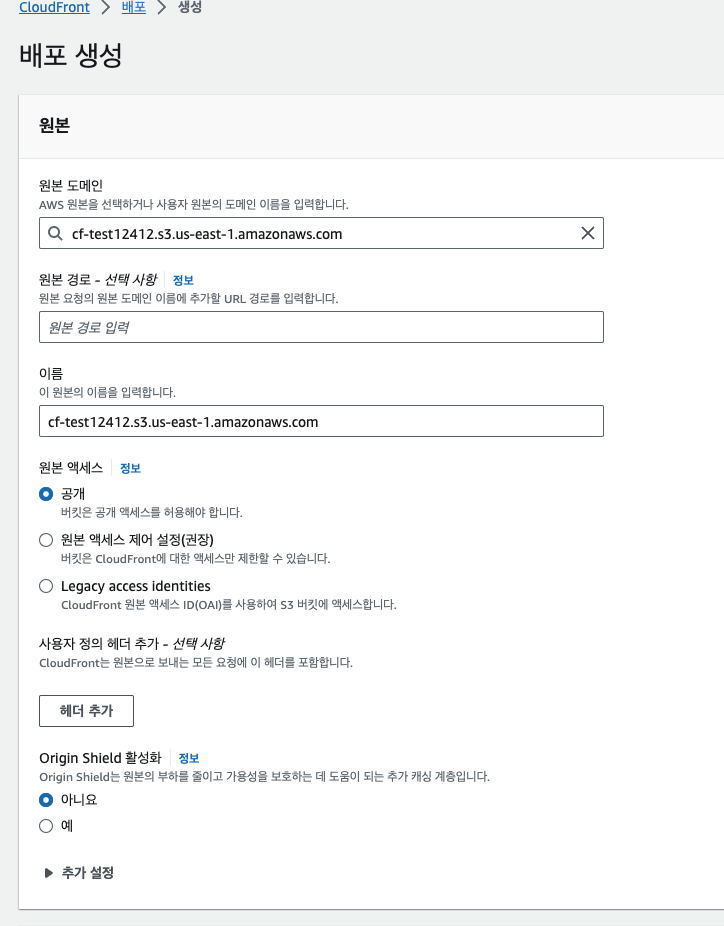
이후 CloudFront에서 배포를 클릭한 뒤, 오리진을 앞서 만든 S3 버킷으로 선택한다. [원본 경로] 옵션은 특정 폴더만 오리진 경로로 지정하기를 원할 때 사용한다. [원본 이름]은 기본적으로 원본 도메인을 그대로 가져와서 사용하지만, 다른 이름을 부여할 수도 있다. 책에서는 [OAI 사용] (Origin access identity) 옵션은 버킷에 있는 콘텐츠를 CloudFront를 통해서만 접근가능하도록 하는 것이라고 설명한다. 다만 해당 기능은 Legacy access identities로 변경되었다. 일단 교재의 내용대로 Legacy access identities 옵션으로 선택해준 뒤 [OAI 생성]으로 OAI를 생성한 후 생성된 원본 액세스 ID를 지정해주었다. [Origin Shield 활성화] 기능은 캐시 적중률을 높이기 위한 계층 추가 옵션인데, 비용이 발생하므로 신중하게 선택해야한다.
캐시 항목 중 [경로 패턴]은 기본값 '*'를 기반으로 정규표현식으로 모든 문자를 포함하는 옵션이다. [자동으로 객체 압축]은 콘텐츠를 오리진에서 전송할 때 압축 여부를 결정한다. [뷰어 프로토콜 정책]은 HTTP 요청도 HTTPS로 보내기 위해서 [Redirect HTTP to HTTPS]를 선택해준다. HTTP 허용 방식은 [GET, HEAD]로 선택한다. [뷰어 액세스 제한]을 만약 Yes로 처리하면 EC2 접속 시 .pem 파일이 필요한 것처럼 오로지 권한을 부여받은 사용자만 signed URL을 통해서 CloudFront에서 호스팅 하는 서버를 사용할 수 있게 된다. 일단 No로 설정한다.
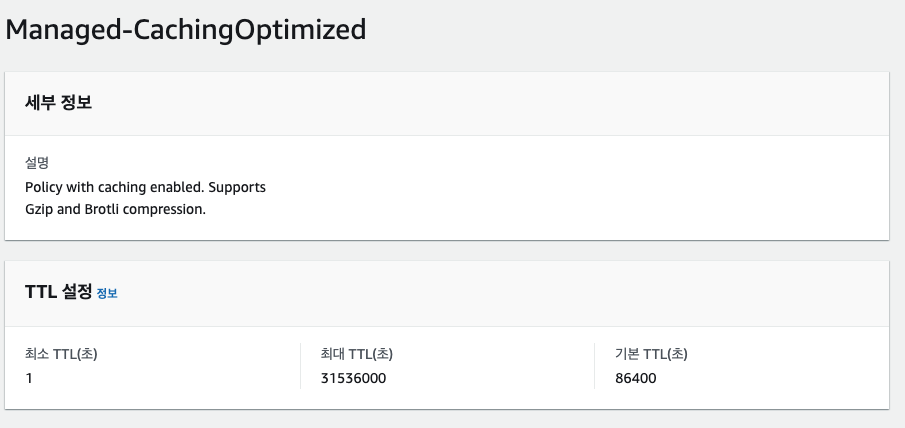
캐시 설정에서는 TTL(Time To Live)를 설정할 수 있다. [CACHE Policy and origin request policy] 옵션을 사용한다. 정책 보기 버튼을 눌러보면 정책이 최대 31536000초(365일), 기본 86400초(24시간) 임을 볼 수 있다. [원본 요청 정책]은 CORS 설정 내용이며 따로 공부가 필요하다.
[함수 연결]은 CloudFront 함수와 Lambda 엣지 오리진으로 나뉘는데, 큰 차이는 없으며 요청이 왔을 때 전처리에 사용된다.
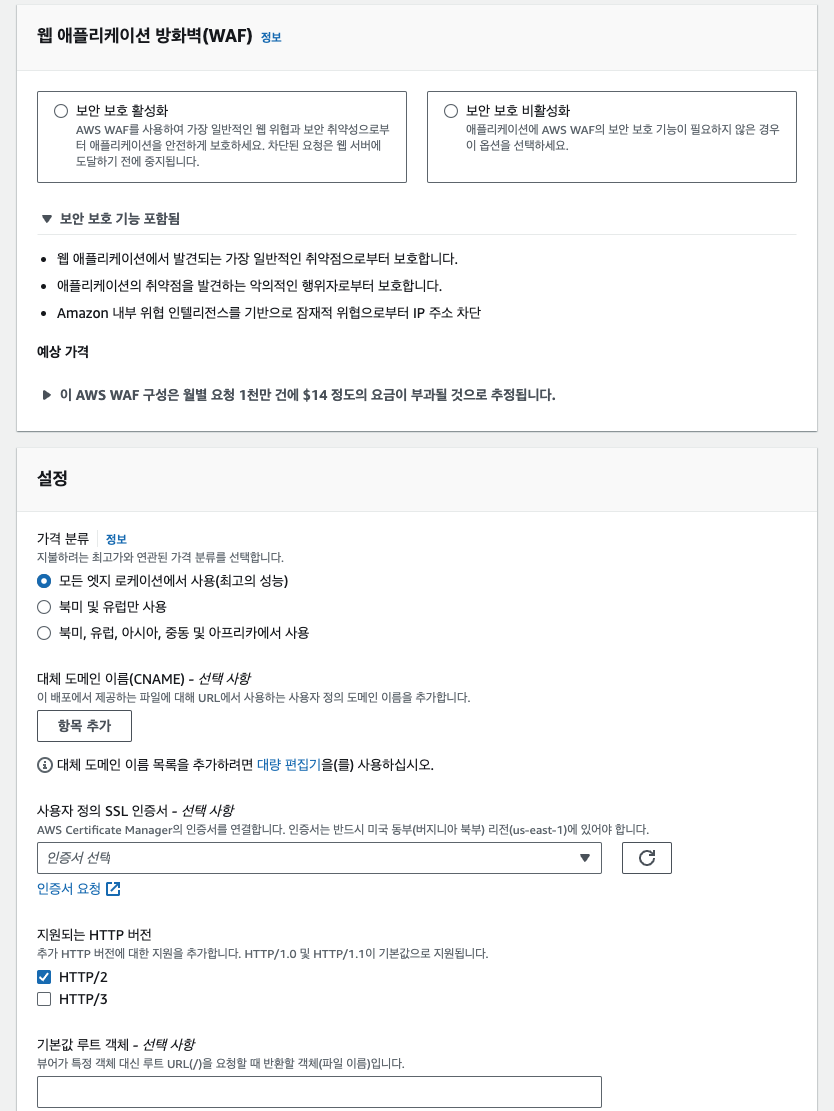
[웹 애플리케이션 방화벽(Web Application Firewall, WAF)] 옵션은 비용이 발생하기 때문에 실습상에서는 비활성화 처리하였다. 그리고 설정에서 [가격 분류]는 얼마나 많은 엣지 로케이션에 배포를 하느냐하는 문제이며, 많은 지역을 포함시킬수록 비용이 커지게된다. [대체 도메인]은 이미 보유중인 홈페이지 도메인이 있다면 여기에 추가하여 연결시킬 수 있는 기능이다. [사용자 정의 SSL 인증서]는 생성한 SSL를 통해 HTTP 요청을 HTTPS로 바꿔주는 기능이다. 다만 이 SSL 인증서를 AWS Certificate Manager에 업로드해야하고 반드시 북부 버지니아 지역이여야 한다. 인증서 요청 버튼을 통해 홈페이지 URL을 입력하고 인증서를 연결시킬 수 있으나, 아직 URL이 없으므로 불가하다.
나머지 옵션들은 디폴트로 지정한 뒤 [배포 생성] 버튼을 누른다.
배포 완료 이후에 CloudFront의 메인페이지에서 '원본' 탭에 들어가보면 [원본 생성]을 할 수 있다. S3외 EC2 인스턴스로 오리진을 추가할 수 있다. 최대 3개 까지 만들 수 있다. 나머지 각 탭에서 CloudFront를 생성할 때 설정했던 설정 부분을 확인할 수 있다. [오류 페이지]는 각종 오류에 대한 응답 페이지를 설정하는 부분이다. [지리적 제한]은 특정 국가의 사용자를 차단할 수 있는 기능이다. [무효화]는 엣지 로케이션에 있는 캐시를 삭제할 수 있는 기능이다. 컨텐츠가 오리진에서는 업데이트 되었는데, TTL로 인해 캐시 파일이 엣지 로케이션에만 남아있는 경우 이 무효화를 통해서 캐시를 비울 수 있다. 다만 무효화 시 비용이 발생하므로 TTL의 시간을 적절하게 잘 설정해야한다!
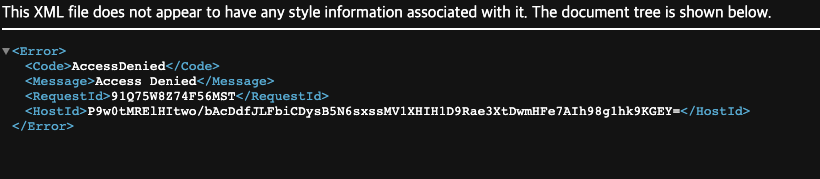
CloudFront에서 URL로 접근할 것이라 버킷의 [퍼블릭 액세스 접근 차단] 기능을 활성화 해준다. 해당 버킷의 '권한' 탭에서 설정해줄 수 있다. 그리고 앞서 업로드한 이미지의 URL을 클릭해보면 AccessDenied 페이지가 뜨는 것을 볼 수 있다.
이제 CloudFront로 객체에 접근해본다.
객체 주소
https://cf-test12412.s3.amazonaws.com/c840a38d-c520-4b4a-a77c-d763869f2824.jpeg
에서 객체 key값만 남기고 앞쪽 주소는 cloudfront의 '배포 도메인 이름'으로 변경해준다.
https://d3v3i8detr742.cloudfront.net
배포 도메인 이름 뒤에 객체 key값을 붙여준다. 그리고 프로토콜도 http로 변경해서 https로 리다이렉트되는지 확인해본다.
http://d3v3i8detr742.cloudfront.net/c840a38d-c520-4b4a-a77c-d763869f2824.jpeg
나의 경우 이미지가 잘 호출되었다. 처음엔 느리게 이미지가 로딩되었는데, 새로고침을 하니 엣지 로케이션의 캐시 기능 덕분에 시크릿 모드로 다시 접속해도 빠르게 이미지가 불러와지는 것을 확인했다.
8. DynamoDB
NoSQL
AWS에서 제공하는 NoSQL(Not Only SQL)이다. NoSQL은 비정규적이고 방대한 양의 데이터를 저장하는데 유리하다. 정규화 과정을 거치지 않은 데이터이므로 중복 데이터(duplicated data)가 존재하며 다른 테이블과 합치는 과정(join)이 필요없기 때문에 읽기 쿼리 속도가 극대화된다.
NoSQL의 데이터베이스 포맷
- 문서 데이터베이스: 주로 JSON 형태의 문서. 필드와 값으로 이루어진다.
- Key-Value 데이터베이스: 문서 데이터베이스와 비슷하지만 구조가 간단하다. JSON 형태이다.
- 그래프 데이터베이스: 노드와 엣지 형식으로 데이터를 보관한다.
특징
DynamoDB는 오토스케일링 기능이 있어서 데이터의 크기에 따라 테이블의 크기가 자동으로 변경되며, 데이터의 처리량에 따라 성능을 변경시킨다. IoT 등 실시간으로 방대한 양의 데이터가 들어오고, 들어올 데이터의 양을 미리 알 수 없을 때 유용하다. SSD 스토리지를 사용하여 데이터를 읽고 쓰는 속도가 더욱 빠르다.
파티션키와 복합키
NoSQL 베이스이기 때문에 처음 생성 시 개체와 속성을 미리 정의하지 않는다. 기본키만 정의하면 된다. DynamoDB의 기본키는 파티션키(partition key)와 복합키(composite key)로 구성된다. 파티션키는 SQL에서 사용하는 PK와 같은 개념이며 키를 바탕으로 해시함수를 적용하여 각 아이템을 여러 개의 스토리지에 분산하여 보관한다. 테이블에 있는 데이터를 파티션으로 나누고 분리시키는데 사용한다. 쿼리 성능 확보를 위해 카디널리티가 높은 속성(주로 id값)을 파티션키로 사용한다. 복합키는 파티션키와 정렬키를 합친 개념이다. 주로 날짜와 같이 정렬이 가능하면서 카디널리티가 상대적으로 높은 값을 정렬키로 설정한다. DynamoDB의 기본키는 파티션키 혹은 복합키여야하며, 정렬키만 단일로 기본키로 설정할 수 없다.
권한부여
특정 부서, 유저에게 특정 테이블의 아이템만 공개하고 싶은 경우 IAM에서 역할을 할당해줄 수도 있다.
인덱스
인덱스를 지정하면 쿼리 시 테이블 전체를 스캔하지 않고 특정 열을 기준으로 스캔한다. 인덱스를 생성하면 테이블에서 뷰를 생성한다. 뷰는 실제로 테이블의 데이터가 있는 것이 아니라서 수정이 불가하고 조회에만 활용된다. 다만 테이블이 업데이트되면 뷰도 같이 업데이트 된다. 인덱스를 정의하면 인덱스를 기준으로 테이블에 대한 참조 정보인 뷰를 만든다는 것을 기억하자.
로컬 보조 인덱스(Local Secondary Index, LSI)
테이블을 생성할때만 정의할 수 있으며 변경이 불가하기 때문에 생성할 때 매우 주의해야한다. 파티션키와 정렬키를 함께 사용하는 복합키 형태로 작성한다.
글로벌 보조 인덱스(Global Secondary Index, GSI)
테이블 생성 후에도 추가, 변경, 삭제가 가능하며 파티션키와 정렬키를 원래 테이블의 키들과 다르게 정의할 수 있다. 정렬키는 선택사항이다.
정렬키를 이용해서 테이블에 지정된 하나의 파티션키를 기준으로 주로 쿼리를 한다면 LSI를, 정렬키를 선택사항으로 두고 여러 파티션키를 통해 쿼리한다면 GSI를 사용하는 것이 권장된다.
쿼리와 스캔
일반적인 방식인 쿼리는 테이블의 일부만 조회하여 데이터를 가져온다. DynamoDB에서 제공하는 스캔은 테이블의 모든 데이터를 조회하여 1MB씩 배치로 가져온다. 병렬적으로 스캔하여 가져오지만, 아무래도 쿼리 방식에 비해 부하가 크고 속도가 느리다.
실습
DynamoDB에 접속하여 테이블을 생성한다(서울 리전 체크도 잊지말자). 생성할 스키마는 다음과 같다.
customer_id(String), item_category(String), price(Integer), transaction_date(String)
이중 파티션키는 customer_id, 정렬키는 transaction_date로 설정한다.
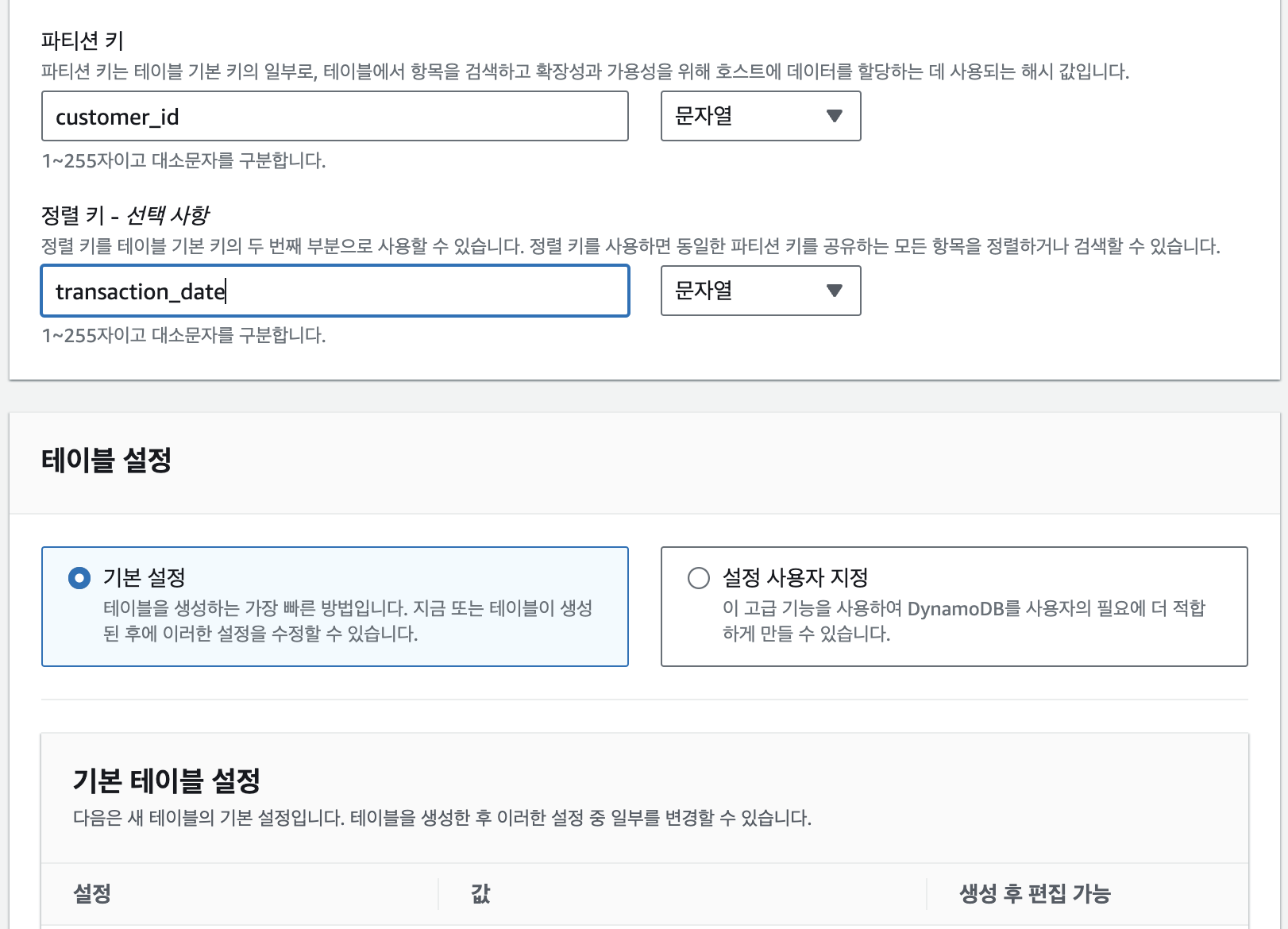
설정에서 설정 사용자 지정을 클릭하면 S3 버킷의 IA(Infrequent Access)처럼 DynamoDB를 설정할 수도 있다. 기본 설정으로 설정한 뒤 테이블 생성을 클릭한다.
콘솔에서 데이터추가
생성하여 활성화된 테이블의 이름을 클릭해서 테이블에 접근 후, [표 항목 검색] 버튼을 누르고 [항목 생성] 버튼을 누르면 데이터를 추가할 수 있다. [새 속성 추가] 버튼을 눌러서 item_category, price를 추가해준다.
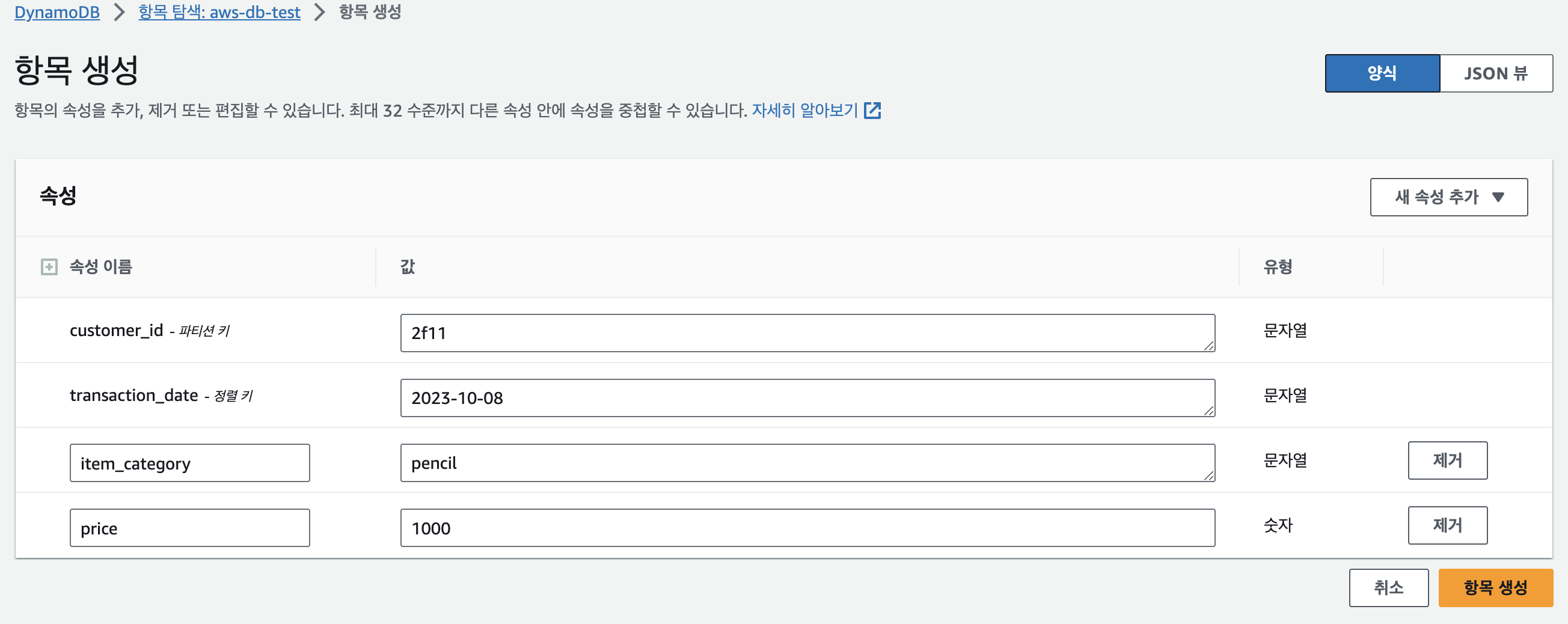
람다함수로 데이터추가
콘솔에서는 한 번에 1개씩만 데이터를 추가할 수 있다. 람다함수를 활용해 배치로 데이터를 넣어본다.
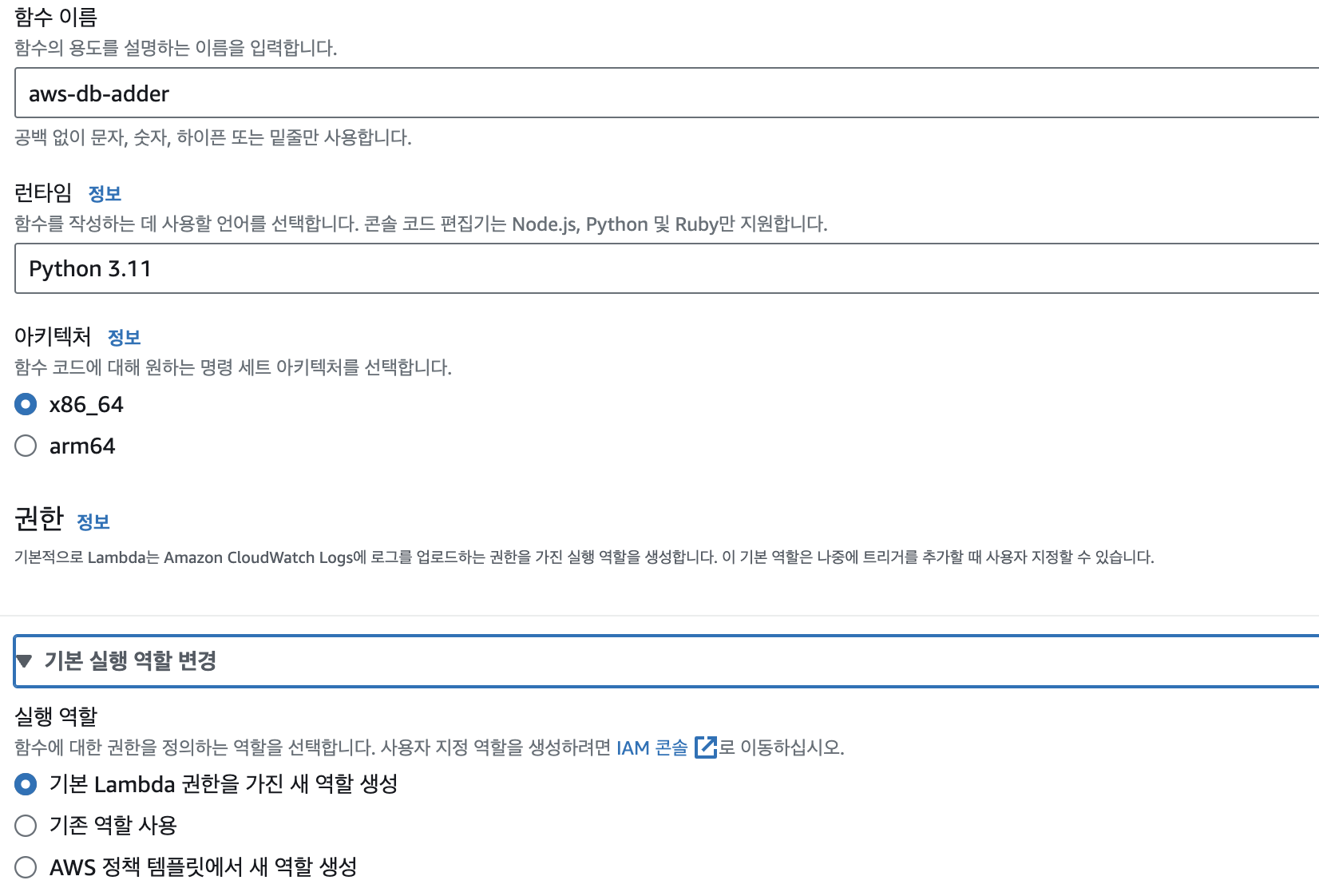
IAM 콘솔로 이동한 뒤 Lambda - [정책 생성] - DynamoDB 검색 - 작업 - '쓰기' 분류 중 PutItem 항목만 체크한다. 그 다음 '리소스' 항목 중 모든 리소스를 클릭한다. 원래는 특정 리소스를 선택하여 특정 테이블에만 정책을 적용할 수 있으나, 실습에서는 테이블이 1개뿐이기 때문에 그냥 모든 리소스를 클릭해주었다. 이후 다음 버튼을 누르고 정책 이름을 설정한 뒤 정책 생성을 마무리한다.
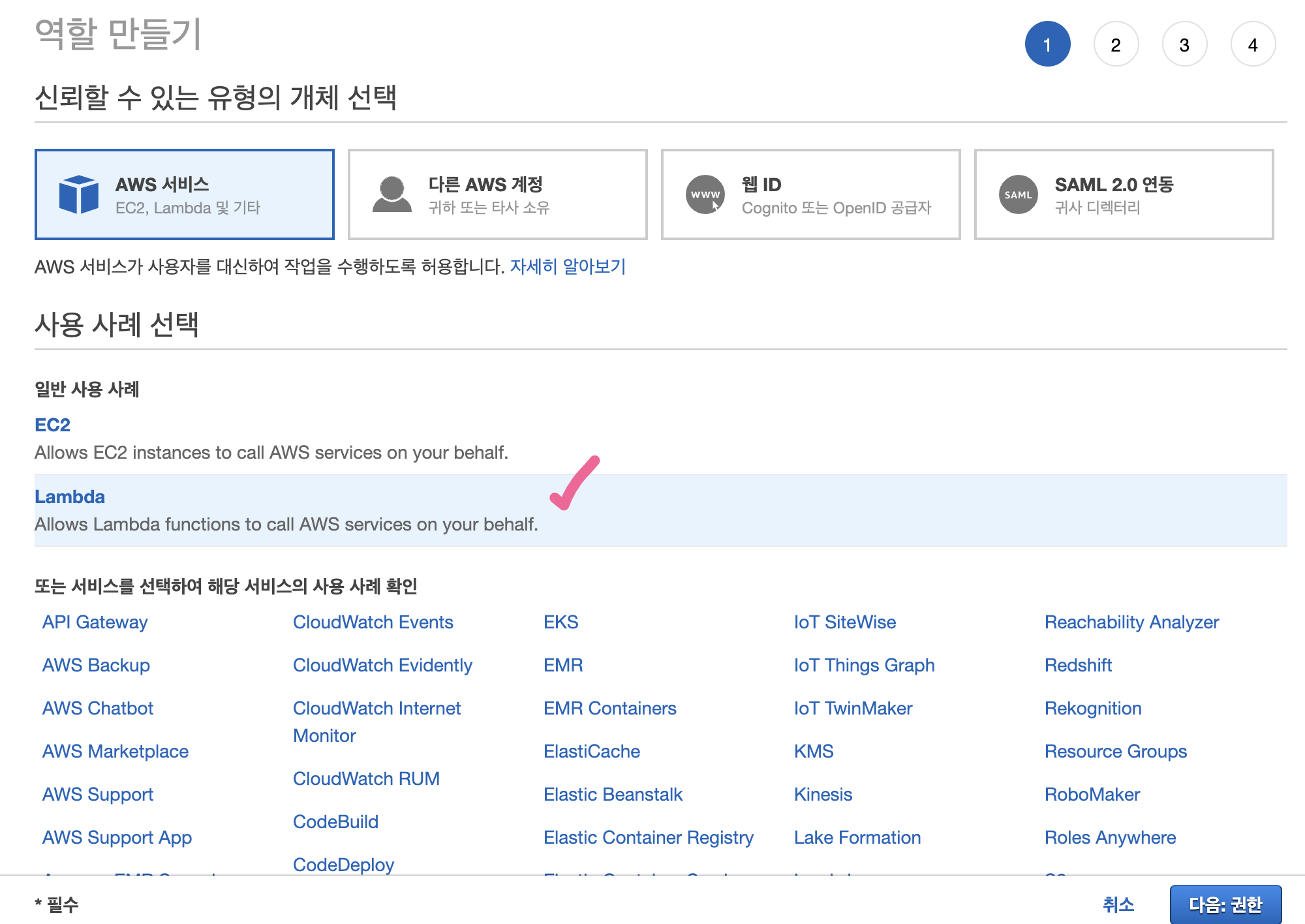
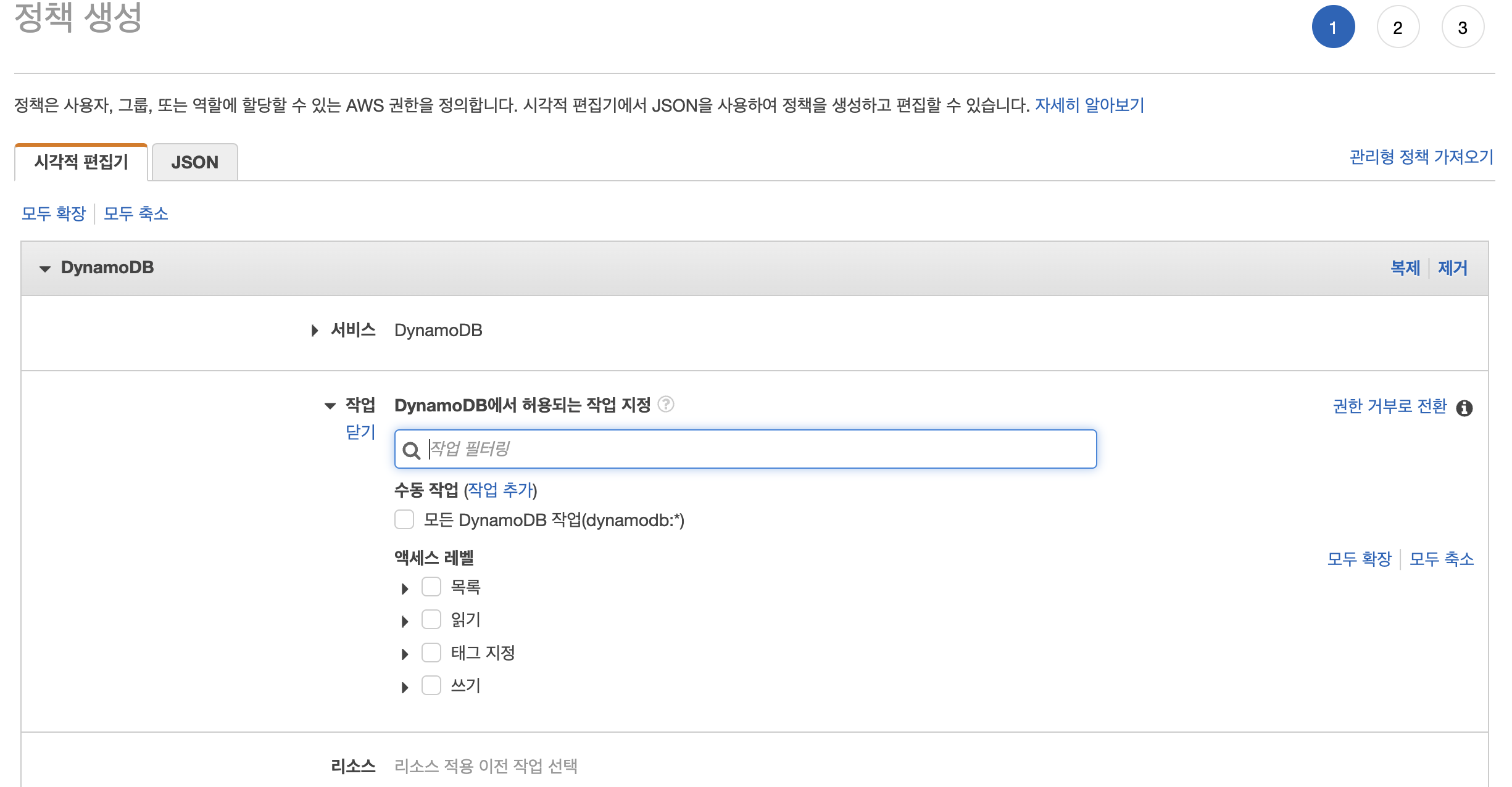
이제 역할을 만들고 위에서 생성한 정책을 연결시킨 다음, 해당 역할을 람다에 부여해서 DB에 접근하고, 쓰기 작업을 할 수 있도록 한다.
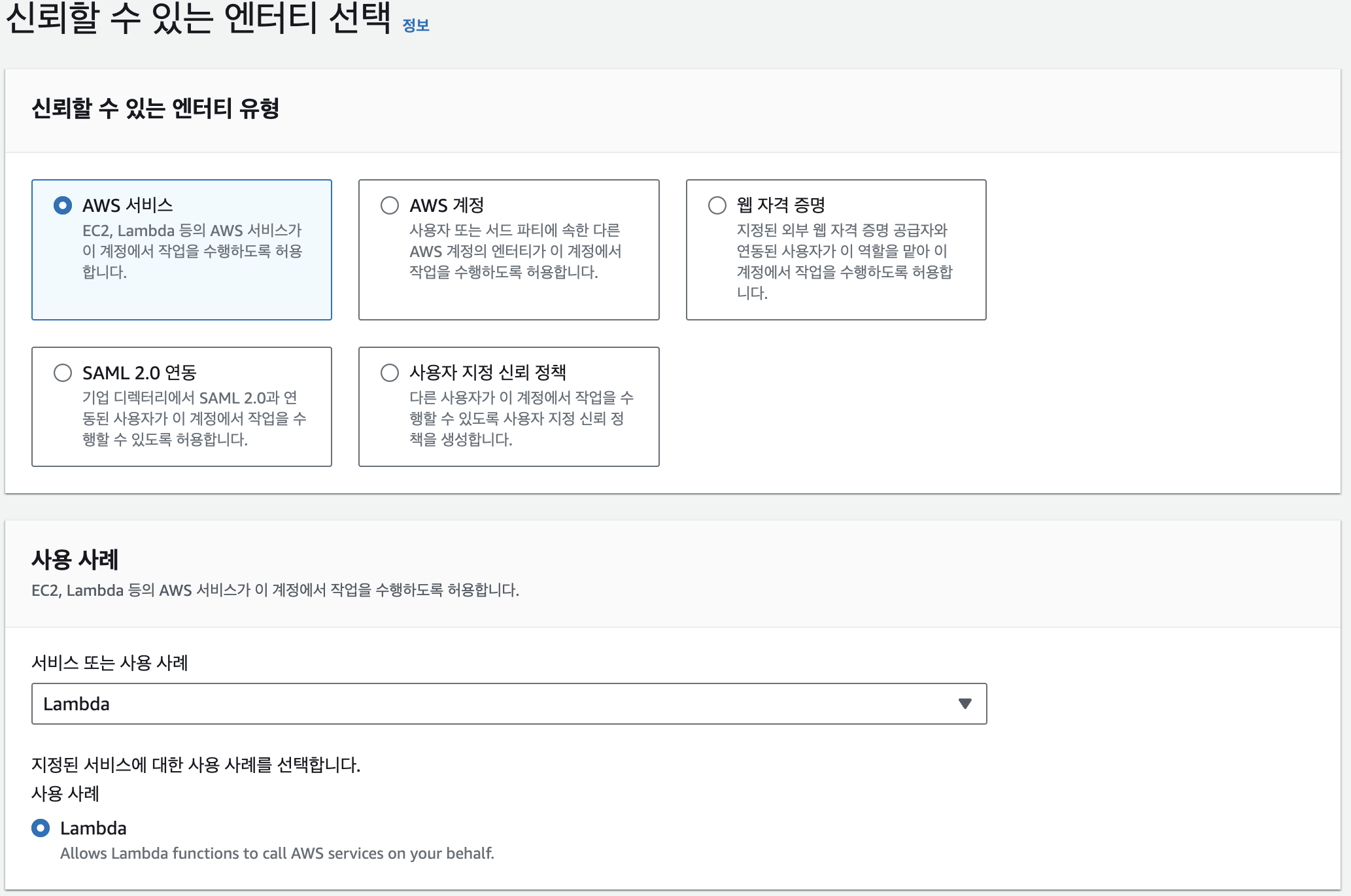
그리고 역할을 만들때, [권한 추가] 부분에서 앞서 생성한 정책 외 람다에서 기본적으로 필요로하는 AWSLambdaBasicExecutionRole을 추가해준다.
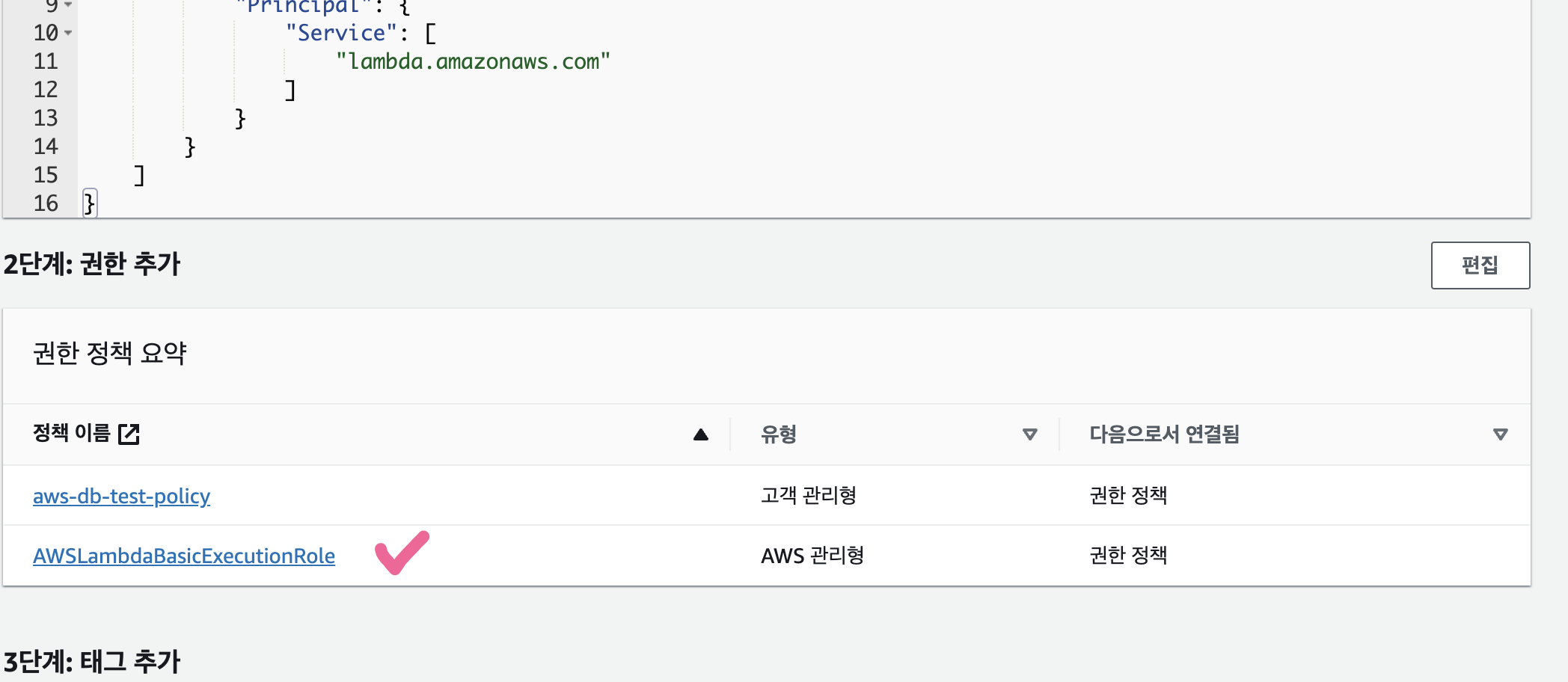
이후 다시 Lambda 생성화면으로 돌아가서 '기존 역할 사용' 부분에서 위에서 추가한 역할을 추가해준다.
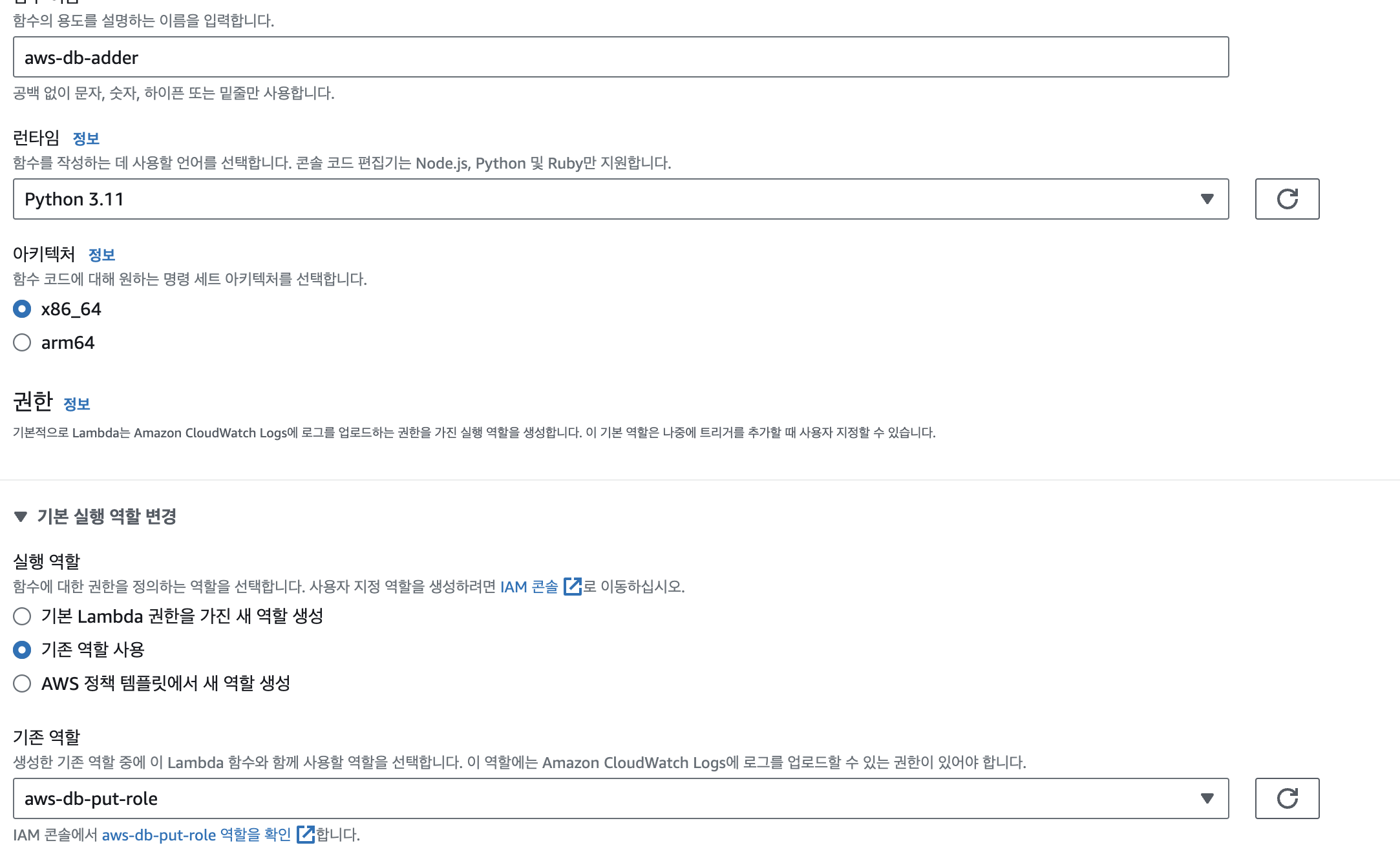
함수 생성 후 아래 코드를 함수 코드에 작성해주어 업데이트한다. 여기서 테이블 이름은 본인이 생성한 이름으로 변경해줘야한다.
import boto3
def lambda_handler(event, context):
client = boto3.resource('dynamodb')
table = client.Table('aws-db-test') # 테이블 이름 업데이트
table.put_item(
Item={
'customer_id': '12MCX',
'transaction_date': '2020-08-02',
'item_category': 'Book',
'price': 18000
}
)함수를 Deploy하고, Test 버튼을 눌러서 환경설정은 그대로 두고 이름만 아무 이름으로 설정 후 저장 -> Test를 눌러 Lambda를 실행한다.
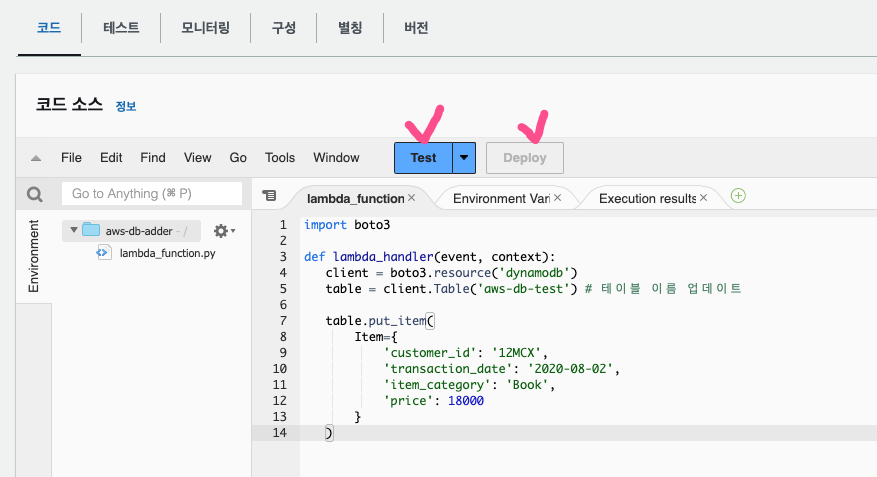
정상적으로 처리되면 DynamoDB에 데이터가 삽입된 것을 확인할 수 있다.
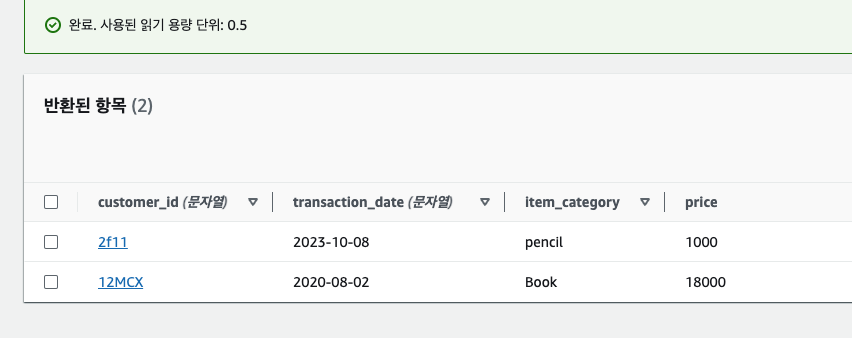
배치 프로세스도 교재에서 주어진 코드로 테스트해볼 수 있다.
import boto3
def lambda_handler(event, context):
client = boto3.resource('dynamodb')
table = client.Table('aws-db-test') # 테이블 이름 업데이트
with table.batch_writer() as batch:
batch.put_item(
Item={
'customer_id': '95IUZ',
'transaction_date': '2020-10-24',
'item_category': 'Desk',
'price': 120000
}
)
batch.put_item(
Item={
'customer_id': '72MUE',
'transaction_date': '2020-10-28',
'item_category': 'Chair',
'price': 250000
}
)
batch.put_item(
Item={
'customer_id': '28POR',
'transaction_date': '2020-11-05',
'item_category': 'Shampoo',
'price': 50000
}
)
batch.put_item(
Item={
'customer_id': '43NCH',
'transaction_date': '2020-10-12',
'item_category': 'Pulse',
'price': 320000
}
)
그런데 나의 경우 BatchWriteItem 권한이 없다는 에러가 떴다. 그래서 람다에서 역할에 정책을 추가해주었다.
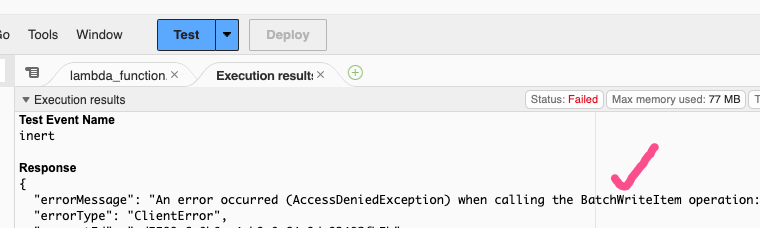
람다 - 구성 - 권한 - 역할 이름 클릭
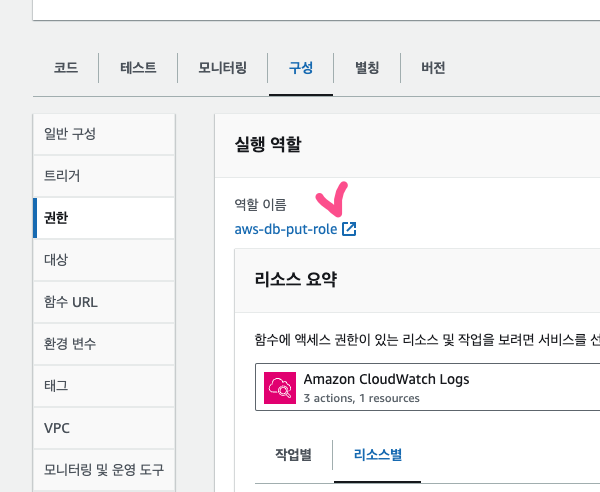
역할 - 권한 - 추가했던 정책 - 편집
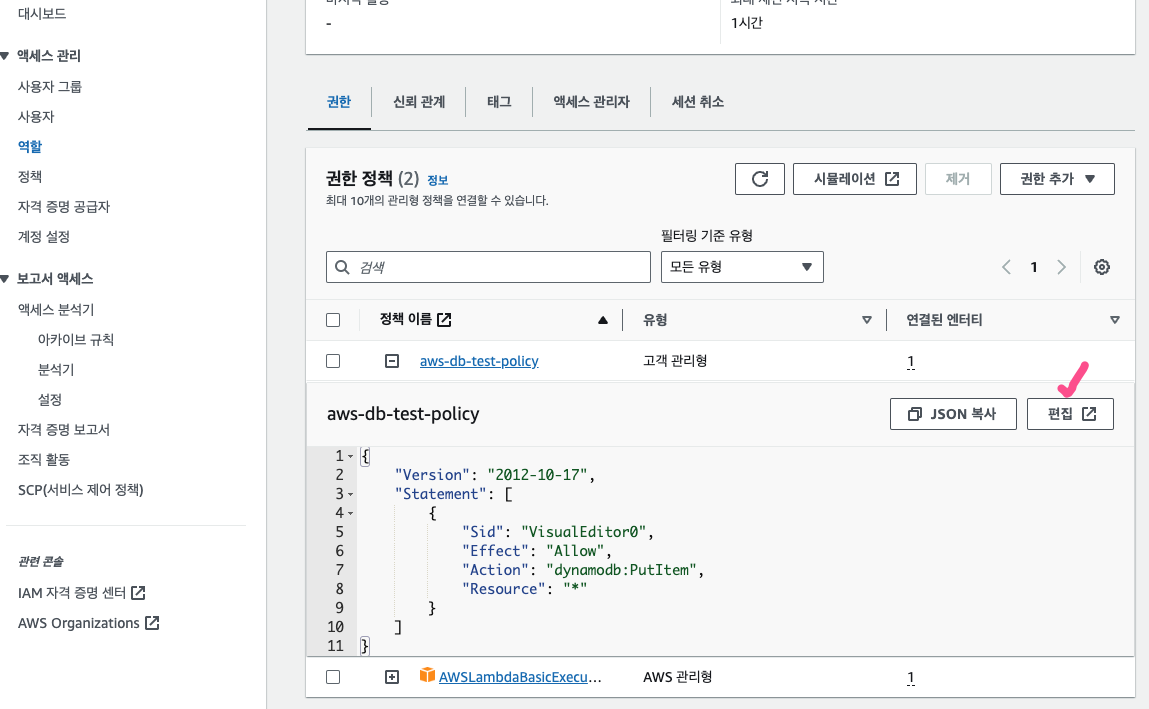
JSON - Action 부분에 dynamodb:BatchWriteItem 권한을 추가로 넣어주고 저장했다.
이후 다시 Test를 진행하니 정상적으로 데이터가 삽입된 것을 확인할 수 있었다.
쿼리 조회는 [표 항목 탐색] 부분에서 배운대로 스캔 또는 쿼리 옵션으로 진행하면 된다. 필터를 줄 수 있고, 속성값은 파티션키와 정렬키 외에 직접 price 처럼 적어주어서 조건을 줄수도 있다.
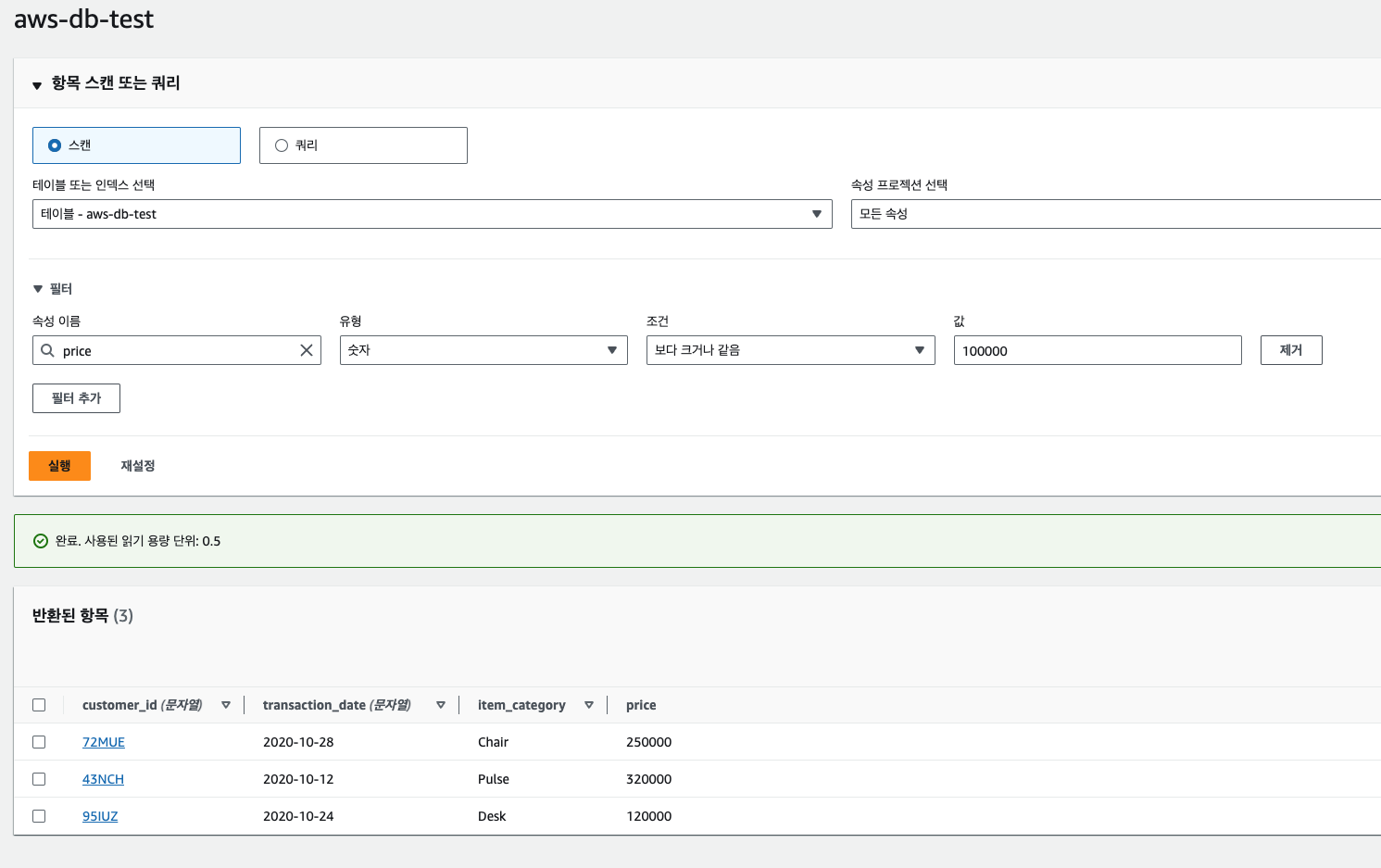
다음 9장 API Gateway에서 상기 생성한 DynamoDB를 그대로 활용할 것이므로 삭제하지말고 일단 유지하고 있자.
9. API Gateway
API Gateway는 서버의 외부와 소통하는 창구 역할을 한다. 권한, 모니터링, 캐싱 시스템 기능 등을 제공한다. 서버의 앞과 뒤에서 여러가지 기능을 처리하는 것이다. API Gateway를 사용만 한다고 비용을 지불하지 않고 페이고(Pay as you go, 번만큼 쓴다) 원칙에 따라서 API 서버의 요청 처리 시간에 따라서 비용을 지불한다.
실습
우선 8장에서 사용한 DynamoDB를 그대로 사용할 것이다. DynamoDB가 없다면 다시 8장을 참고하여 테이블을 만들고 시작한다. 이후 콘솔에서 REST API 서비스에 접속하면 유형에 따라 다르게 선택할 수 있는데, 여기서는 REST API (퍼블릭)를 선택한다. 참고로 REST API 프라이빗은 구축한 VPC 내에서만 API 요청이 가능하도록 하는 형태이다. 회사에서는 보통 이런 방식을 사용하여 사내 VPC에서만 동작하도록 한다. 사내 개발자에게는 VPC 프로그램과 키값을 제공하여 외부에서 VPC에 접속 후 사용이 가능하도록 만든다.
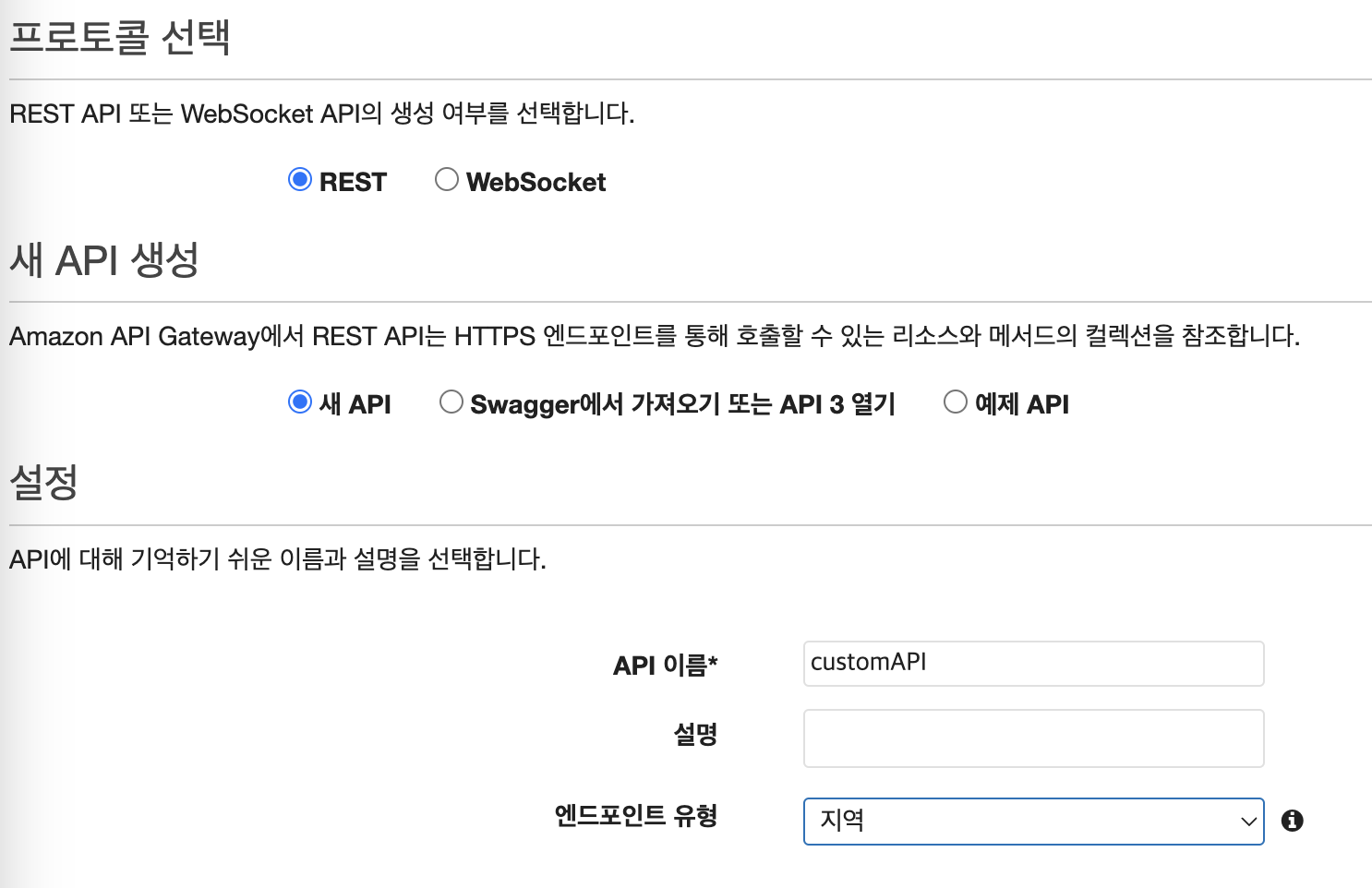
Swagger나 템플릿을 통해서도 만들 수 있지만, 여기서는 새 API를 선택하여 처음부터 만들어본다. 엔드포인트 유형은 지역으로 선택 시 CloudFront의 엣지 로케이션처럼 특정 지역을 의미하는 것이다.
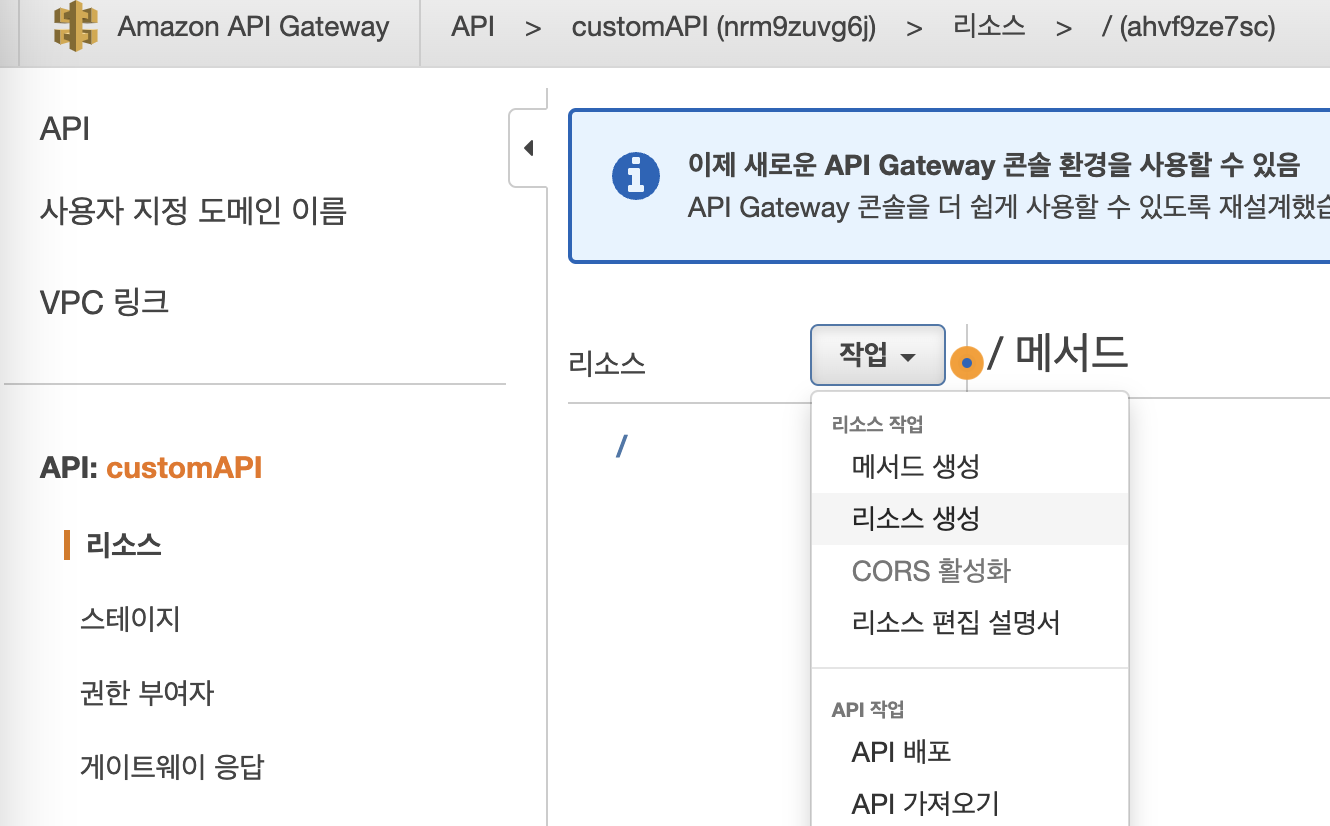
API 생성 후 리소스 - 작업 - 리소스 생성을 눌러 Route를 설정해준다. 그리고 작업 - 메서드 생성을 통해 CRUD를 만들 수 있다.
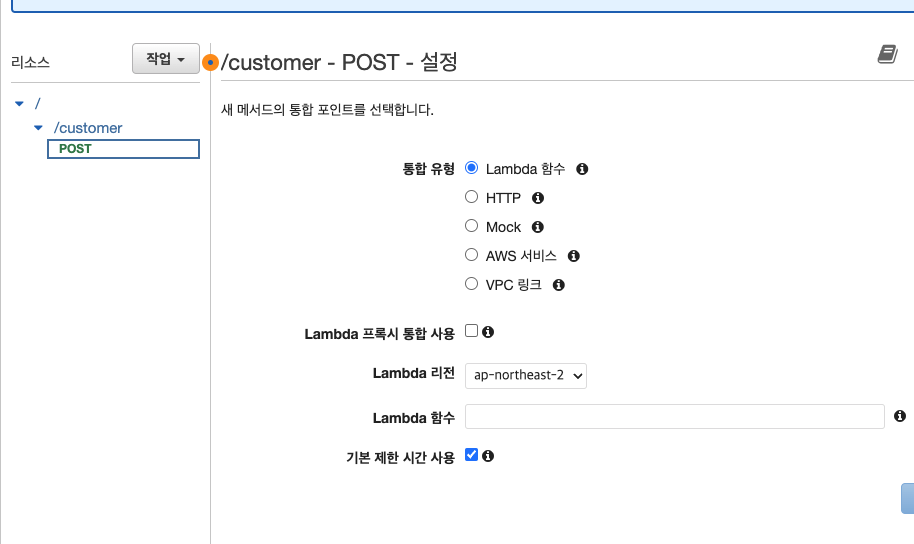
메서드는 POST로 하고 Lambda 함수로 생성한다. 지역은 서울, 런타임은 Python 최신버전, 권한은 9장에서 생성했던 dynamoDB 접근 및 수정 role을 추가해준다. 코드는 아래와 같이 작성한다. 앞서와 마찬가지로 Table 이름은 변경해주어야한다.
https://github.com/kimx3129/Simon_Data-Science/blob/master/AWSLearners/10%EC%9E%A5/addCustomer.py
import boto3
resource = boto3.resource('dynamodb')
table = resource.Table('aws-db-test') # 테이블 이름 변경
def lambda_handler(event, context):
table.put_item(Item=event)
return {"code":200, "message": "Data Successfully Inserted!"}lambda_handler 함수에서 파라미터로 정의한 event는 API Gateway에서 전달받는 API 요청이다.
Deploy를 눌러 람다함수를 배포하고, 다시 API Gateway에 가서 생성한 람다함수의 ARN 값을 복사해서 넣어준다.
lambda에 대한 권한승인을 하면 대시보드형태로 API Gateway 구성요소를 보여준다. 테스트를 눌러 '요청 본문' 부분에 아래의 API 요청 body를 입력한다.

{
"customer_id": "12d12",
"transaction_date": "2023-10-10",
"item_category": "table",
"price": 12500
}
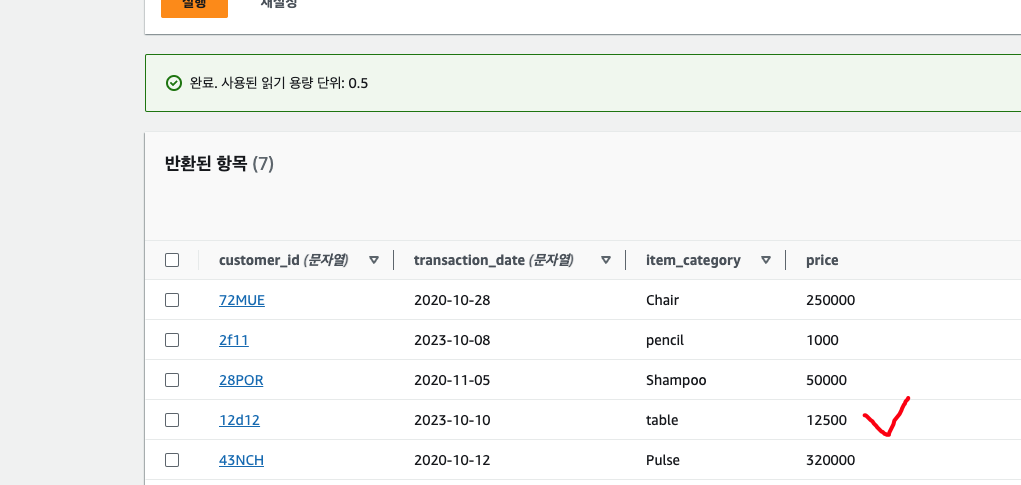
정상적으로 데이터가 삽입된 것을 확인할 수 있었다. POST 이외에 DELETE, UPDATE 등의 메서드도 이와 같은 방식으로 진행하면 된다.
10. CI/CD 파이프라인
CI(Continuous Integration)은 여러 개발자가 중앙의 Repository에 각자의 코드를 충돌없이 병합하여 실수를 줄이고 본인의 코드에 집중할 수 있도록 해주는 시스템을 말한다. CD(Continuous Depolyment)는 변경한 코드를 변경사항이 있을 때마다 배포하여 사용자에게 개선된 기능을 사용할 수 있도록 배포를 자동화하는 개념이다. CI/CD를 통해 코드의 수정과 반영을 자동화할 수 있으며 에러를 줄일 수 있다.
코드 커밋(CodeCommit)
코드커밋은 AWS를 이용한 CI/CD 실습에 기본이 되는 Repository이다. 깃허브와 유사하다.
실습
[리포지토리 생성] 버튼을 누르고 이름을 입력하여 리포지토리를 만든다.
생성 후 연결 방법 중, SSH는 루트 계정으로 생성한 경우 제공되지 않는다. HTTPS(GRC)로 표시된 부분을 사용하면 깃허브에서 사용자 정보를 가져와서 코드커밋과 연동이 가능하다.
테스트를 위해 단순 HTTPS 방식으로 스크롤을 내려서 '파일 추가/파일 생성' 버튼을 누른다. 아무런 내용이나 입력하고 .txt 파일로 만들고, 작성자 이름 및 이메일 주소를 본인의 계정으로 입력 후 커밋 메시지를 간단히 넣어준다.

기본적으로 main 브랜치로 생성된다. main에서 다른 브랜치를 따와서 변경 사항을 반영하는 연습을 해본다. '리포지토리-브랜치- 브랜치 생성' 에 들어가서 새로운 브랜치를 만든다.
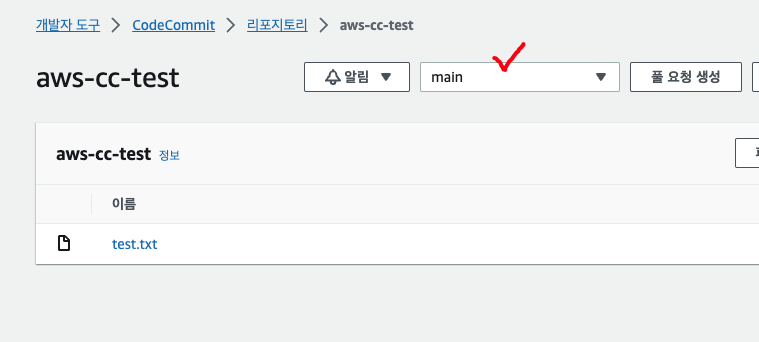
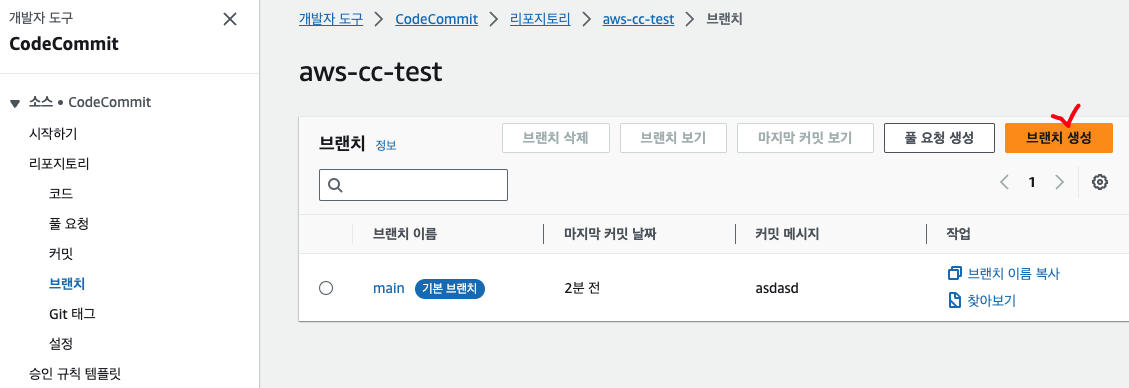
'다음으로부터의 브랜치' 항목은 base가 되는 브랜치를 의미하며 여기서는 앞서 생성한 'main' 브랜치를 눌러주면 된다. 이후 파일을 수정하고, 새로 생성한 브랜치에서 [풀 요청 생성]을 눌러 요청 -> 병합을 하면 된다. gitflow와 같다.
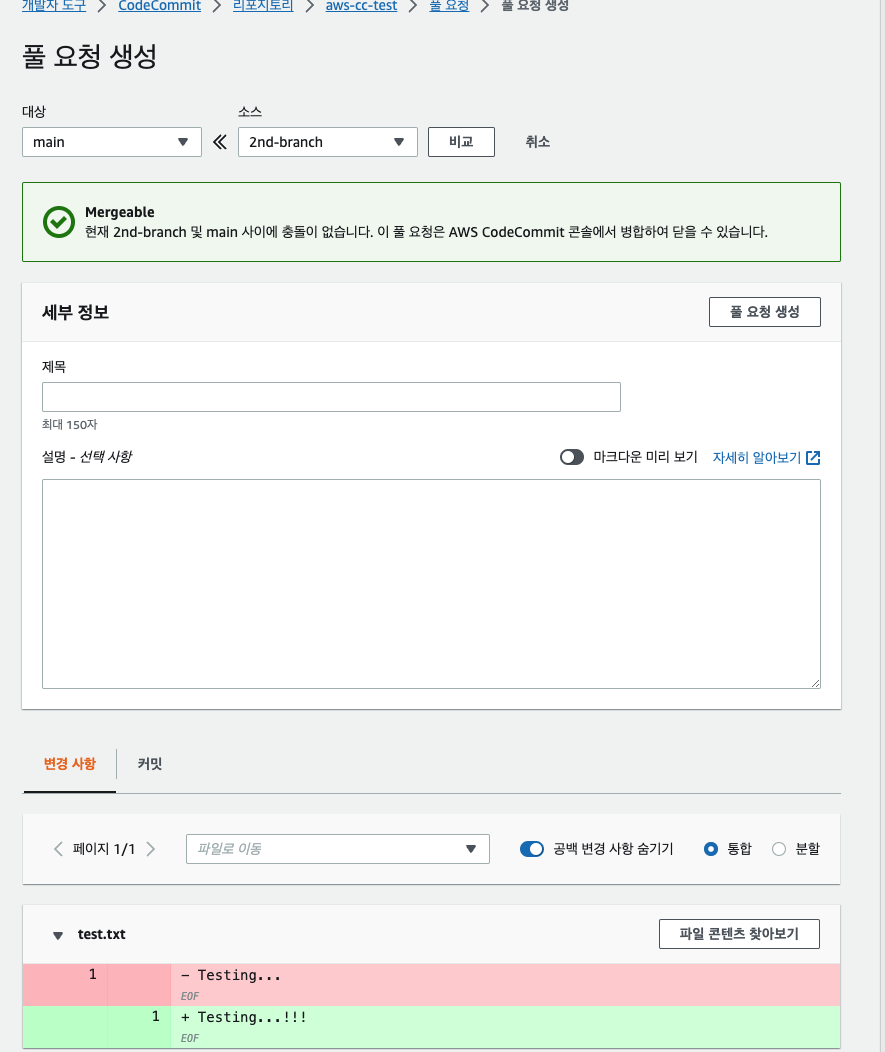
커밋 탭에서 커밋 사항들을 확인할 수 있다.
코드 배포
코드 배포에 대표적인 방식은 2가지가 있다.
- 롤링 배포(rolling deployment): 업데이트 비중을 20%라 정하면 인스턴스 5개 중 1개씩 새로운 인스턴스로 교체되는 방식. 교체 중에 이전 버전의 인스턴스로 요청이 들어와서 데이터가 틀어질 수도 있고, 롤백 시 전체 인스턴스를 하나씩 모두 롤백해야한다는 단점이 있다.
- 블루그린 배포(blue/green deployment): 명칭상 블루는 현재 사용중인 인스턴스, 그린은 새롭게 배포할 인스턴스를 의미한다. 미리 새로운 버전의 인스턴스로만 구성된 그린 영역을 만들어두고, 사용자 요청의 일부를 그린 영역으로 돌린다. 그러다가 최종적으로는 모든 트래픽을 그린 영역으로 돌리고 블루 영역은 제거하는 방식이다. ELB의 설정을 통해 요청 트래픽을 분산한다. 최신 버전으로의 전환이 용이하나, 롤링 배포에 비해 느리고 그린 영역을 만들 때 추가 비용이 발생한다.
앱의 초기에는 롤링배포를 하고, 인스턴스의 개수가 많고 복잡한 인프라를 구성하는 경우 블루그린 배포를 하는 것이 권장된다.
실습
EC2 인스턴스를 생성하고 S3에 있는 소스 코드에 접근하여 배포해보는 실습을 해본다. 무료 크레딧을 모두 사용했다면 EC2를 이용하면서 일부 비용이 청구될 수 있다. 실습 후에는 반드시 인스턴스를 종료해야한다.
실습1. IAM 권한 추가
우선 IAM에서 필요한 역할 및 권한을 생성한다.
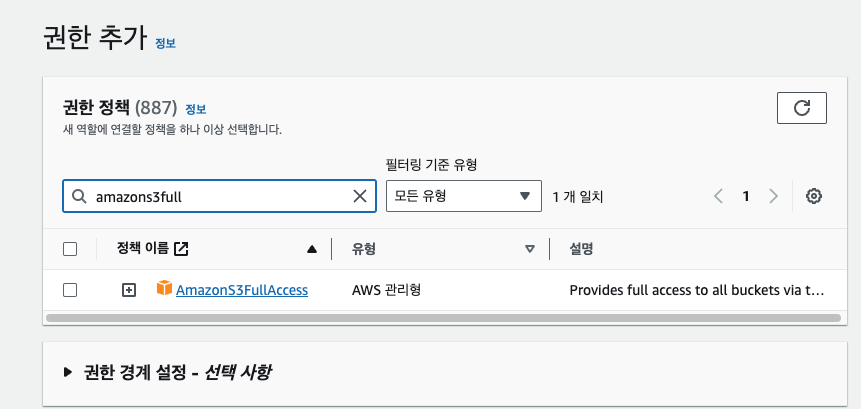
IAM - 역할 - 역할 만들기 - 신뢰할 수 있는 서비스, 사용 사례는 각각 AWS 서비스, EC2를 선택한다.
다음 화면에서 권한은 AmazonS3FullAccess를 추가해주고 역할을 생성한다.
이외에 코드 배포에 필요한 소프트웨어인 CodeDeploy Agent를 EC2에 설치하기 위한 권한을 추가한다.
IAM - 역할 - 역할 만들기 - 신뢰할 수 있는 서비스, 사용 사례는 각각 AWS 서비스, CodeDeploy를 선택한다. 이 경우 권한 정책이 자동으로 AWSCodeDeployRole만 추가된다. 해당 역할도 이름만 지정해서 생성하면 된다.
실습2. EC2 인스턴스에 배포 프로그램 설치
EC2에 들어가서 새로운 인스턴스를 만든다.
Amazon Linux 2 AMI (HVM) - Hernel 5.10, SSD Volume Type으로 설정하고 t2.micro 프리티어로 설정해준다.
키페어는 새로 생성해도 되고, 기존에 만들어놓은걸 사용해도 된다.
네트워크 설정은 [편집]으로 상세화면에 들어가서 설정한다. 퍼블릭 IP 자동 할당을 하고, 보안 그룹 규칙에 사용자 지정으로 HTTP유형의 '0.0.0.0/0'과 '::/0'을 추가해준다.
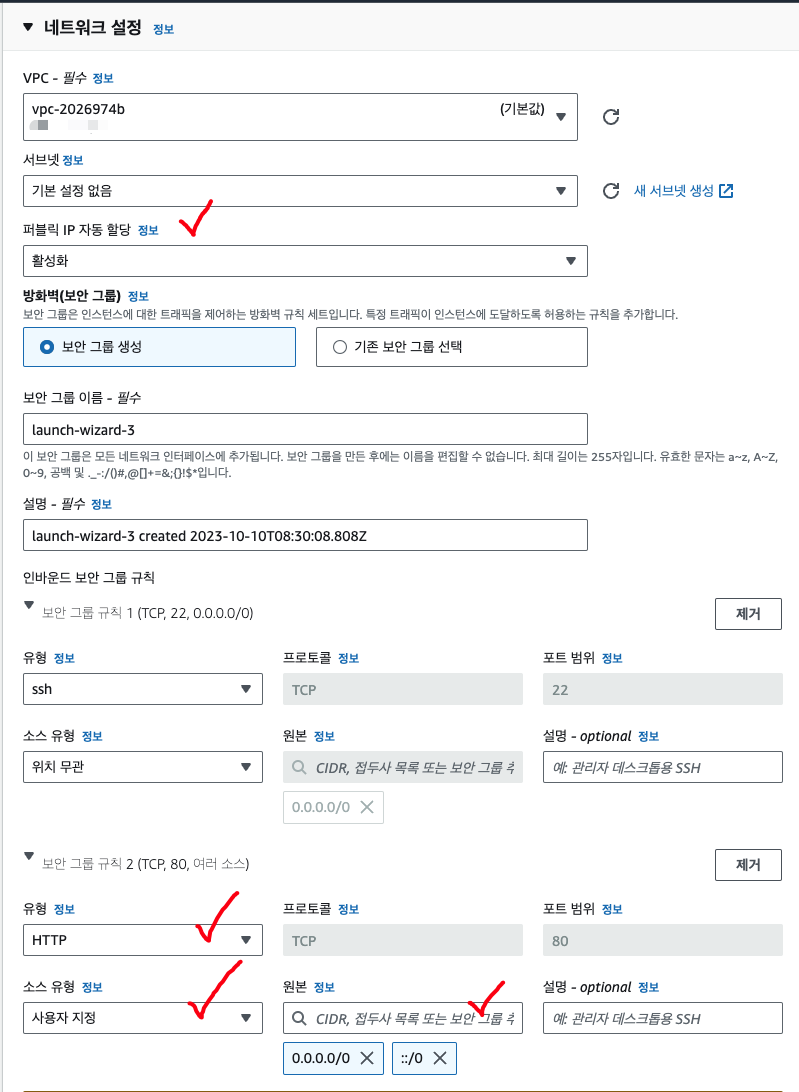
마지막으로 [고급 세부 정보]에 들어가서 IAM 인스턴스 프로파일 부분을 앞서 생성한 s3 접근 role을 선택해준다!
이후 pem 파일의 권한을 변경한다.
chmod 400 <pem 파일>
ssh로 EC2에 접속 후 다음 명령어를 입력한다. 연결 명령어는 EC2의 [연결] 탭에서 바로 확인가능하다.
다음으로 아래 명령어들을 실행한다. 패키지 관리자를 최신으로 업데이트하고, 루비 언어를 다운로드 받은 후 wget을 설치한다. 그리고 '/home/ec2-user' 위치에 CodeDeploy Agent 설치 파일을 다운로드한다.
sudo yum update
sudo yum install ruby
sudo yum install wget
pwd #/home/ec2-user 임을 확인
chmod +x는 리눅스에서 실행가능(excutable) 권한을 추가해준다는 뜻이다.
wget https://aws-codedeploy-ap-northeast-2.s3.amazonaws.com/latest/install
chmod +x install
sudo ./install auto
설치 확인을 위해 다음 명령어를 실행해본다.
sudo service codedeploy-agent status
CodeDeploy is running.. 같은 문구가 나온다면 정상적으로 실행 중인 것이다.
실습3. S3 버킷 생성, 소스코드 입력
우선 배포 정보를 담을 파일들을 로컬에서 생성한다. 터미널에서 ec2에서 exit으로 빠져나온 후 새로운 폴더를 생성하고 파일들을 생성한다.
mkdir code-deploy-ex
cd code-deploy-ex
touch, nano 등의 명령어를 입력하여 코드를 생성해도 되겠지만, 교재에 있는 코드를 복사하여 위 디렉토리에 넣어주면 될 것 같다.
https://github.com/kimx3129/Simon_Data-Science/blob/master/AWSLearners/11%EC%9E%A5/mywebapp.zip
- appspec.yml 파일
files 부분에 내 로컬이 source가 되고, 목적지가 destination이 된다. EC2의 /var/www/html/로 index.html 파일을 보낸다.
hooks 부분은 배포 진행 시 필요한 명령어들을 언제 어떻게 실행할지를 정의하는 것이다. 해당 스크립트들은 순서대로 실행되기 때문에 순서에 신경써서 작성해야한다.
version: 0.0
os: linux
files:
- source: /index.html
destination: /var/www/html/
hooks:
BeforeInstall:
- location: scripts/install_dependencies.sh
timeout: 300
runas: root
- location: scripts/start_server.sh
timeout: 300
runas: root
ApplicationStop:
- location: scripts/stop_server.sh
timeout: 300
runas: root-index.html 파일
'현재 버전은 1.0 입니다' 라는 문구가 출력되도록 되어있다. 이 부분을 업데이트 할 예정이다.
이제 S3 버킷을 생성한다. 객체 소유권은 ACL 비활성화, 리전은 서울, 모든 퍼블릭 액세스 차단은 활성화, 버킷 버전 관리는 비활성화, 기본 암호화는 비활성화 옵션으로 생성한다.
버킷 생성이 완료되면, 교재에서 제공하는 파일을 압축 파일 형태로 S3에 업로드한다. 나중에 이 위치를 기반으로 배포가 되도록 할 것이다.
실습4. 코드 배포
codedeploy - 애플리케이션 - 애플리케이션 생성 버튼을 클릭한다. 이름을 설정하고, '컴퓨팅 플랫폼' 옵션은 어디서/어떻게 코드 배포를 진행할지를 결정하는 옵션이다. 'EC2/온프레미스'를 선택해준다.
배포 그룹 생성을 누른뒤, 이름을 지정해준다. 옵션 정보는 아래처럼 입력한다. '현재 위치'는 롤링 배포를 의미하는 것이다. 그리고 EC2 인스턴스의 키, 값은 미리 만들어놓은 EC2를 가리키게 된다.
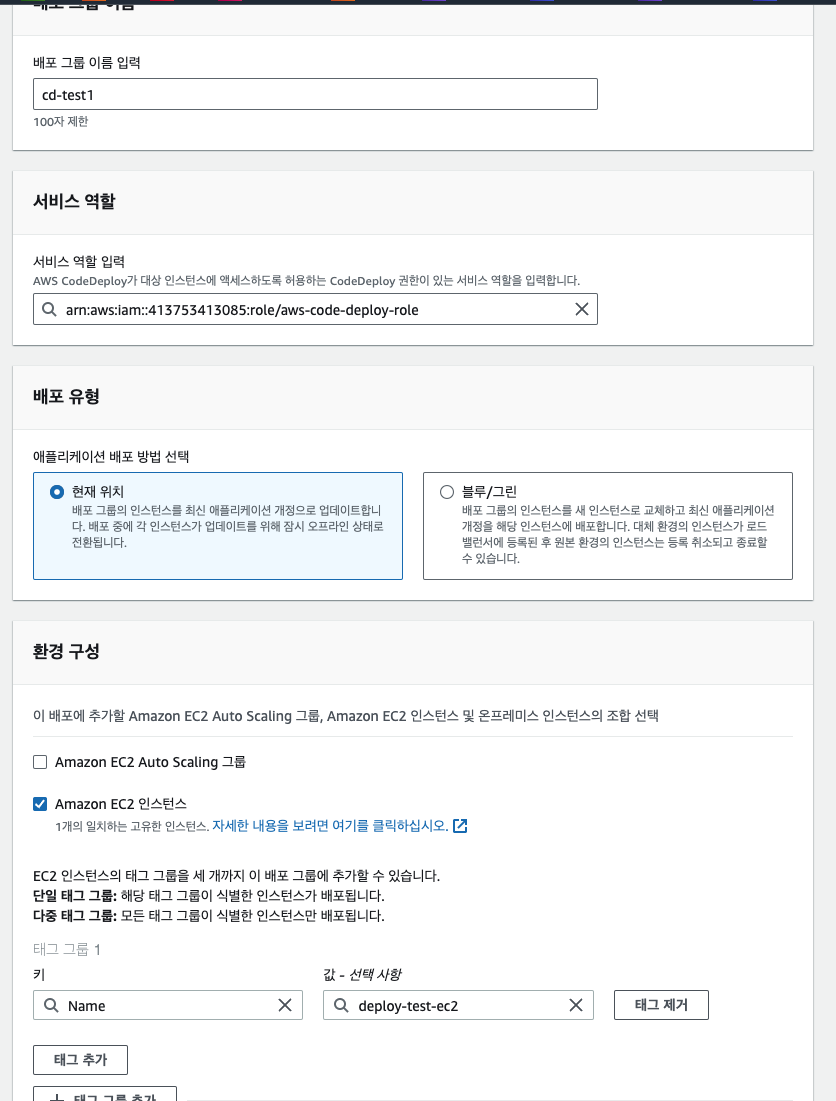
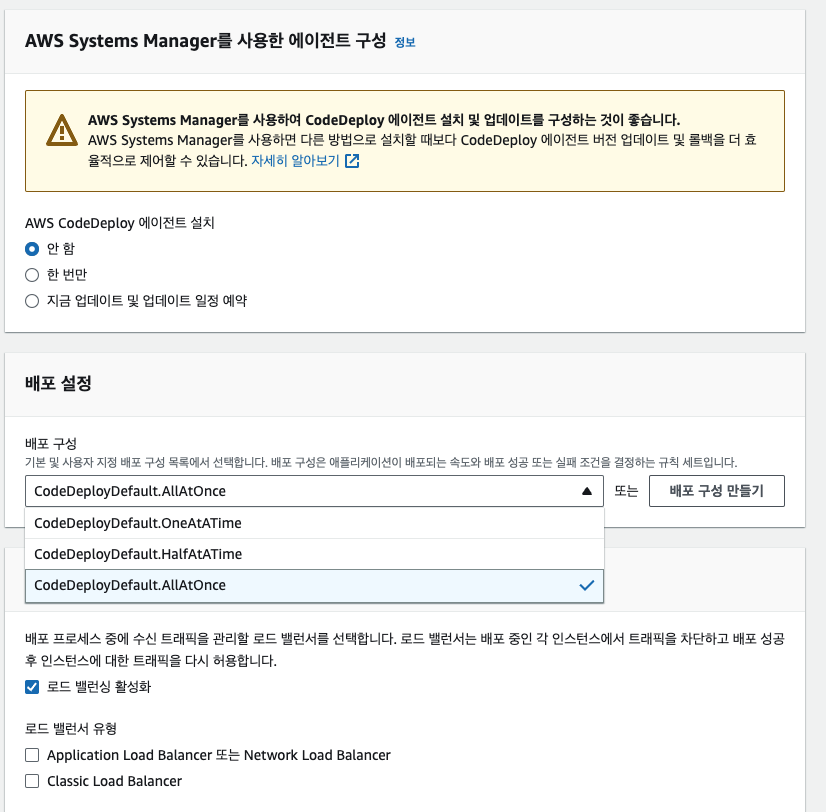
그리고 CodeDeploy 에이전트는 앞서 미리 설치했으므로 '안 함'으로 선택한다. 만약 인스턴스가 여러 개 있어서 모든 인스턴스에서 CodeDeploy를 최신으로 유지하고 싶다면 '지금 업데이트 및 업데이트 일정 예약' 옵션을 선택해주면 된다. 배포 설정은 인스턴스 배포를 한 꺼번에, 절반만, 하나씩 할 것인지를 선택하는 옵션이다. AllAtOnce로 하면 된다. 그리고 인스턴스가 하나밖에 없기 때문에 로드 밸런싱은 비활성화 한다
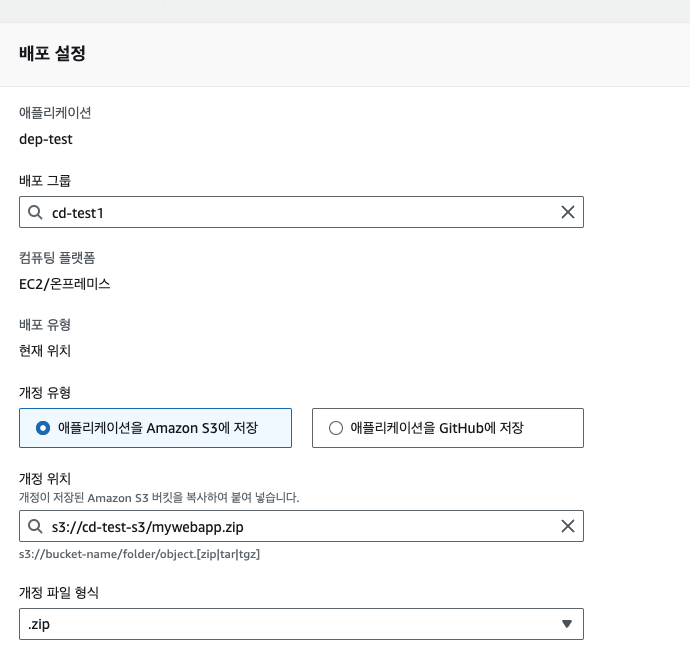
이제 [배포 생성] 버튼을 누른다. 그리고 아래처럼 개정 위치 속성값을 S3에 업로드한 배포 파일의 URI 주소로 넣어준다. 이후 [배포 만들기] 버튼을 누르면 배포가 진행된다.
배포가 성공적으로 이루어졌다면 EC2 인스턴스에서 퍼블릭 IPv4 주소를 브라우저에서 실행할 수 있다.
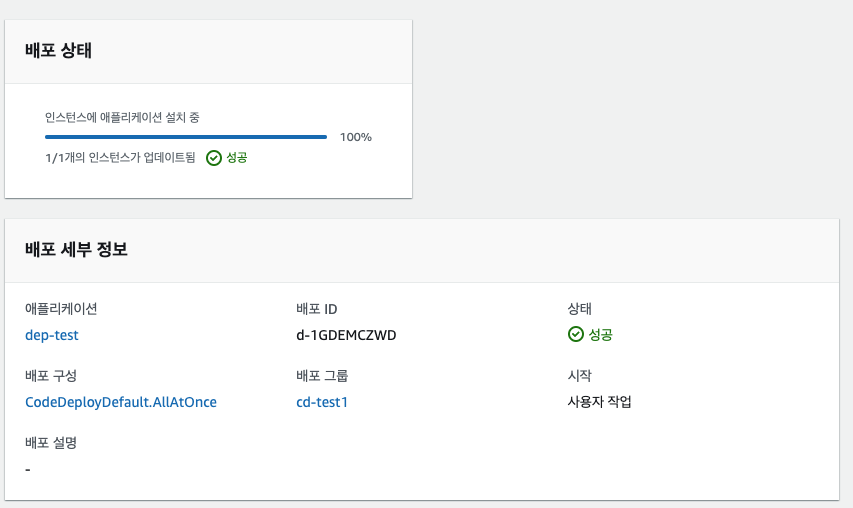

이제 배포 테스트를 위해서 index.html 파일을 수정하여 똑같은 압축파일을 만들고 S3에 다시 업로드한다. macOS라면
nano index.html
명령어로 파일을 수정해보면 된다.
똑같은 이름의 압축 파일을 업로드하면 S3상 오브젝트의 키값이 동일하기 때문에 덮어써진다. 그리고 나서 CodeDeploy에서 다시 배포 그룹을 찾아서 배포 생성, 배포 만들기를 진행한다.(애플리케이션 - 배포 그룹 선택 - 배포 생성 - 앞서와 똑같은 옵션 선택 후 배포 만들기)
이제 다시 접속해보면 페이지가 수정된 것을 확인할 수 있다. 브라우저가 index.html을 캐시하고 있을 수 있으니, 크롬이라면 시크릿 모드로 접속하거나 cache를 날린 뒤에 접속해봐야한다.

실습6. 코드 파이프라인
코드 파이프라인은 배포부터 출시까지의 과정을 자동화하는 단계이다.
- 워크플로(Workflow) 정의 (CodePipeline)
- 리포지토리에서 코드 변경(CodeCommit)
- 컴파일, 테스트, 패키지 생성(CodeBuild)
- 개발 및 프로덕션 환경 배포(CodeDeploy)
콘솔에서 CodePipeline을 찾아서 접속 후 파이프라인 - 파이프라인 생성 버튼을 누른다. 단계별로 진행한다. 먼저 이름을 누르고 다음을 누른다. 소스 스테이지에서는 소스 코드의 위치 및 키 값을 입력한다. 변경 감지 옵션은 CloudWatch Event 옵션을 선택하는 경우 S3에 파일이 업로드되는 event를 감지하여 자동으로 파이프라인이 작동하도록 하는 것이다. AWS CodePipeline 옵션은 수동으로 파이프라인을 실행시키는 옵션이다.
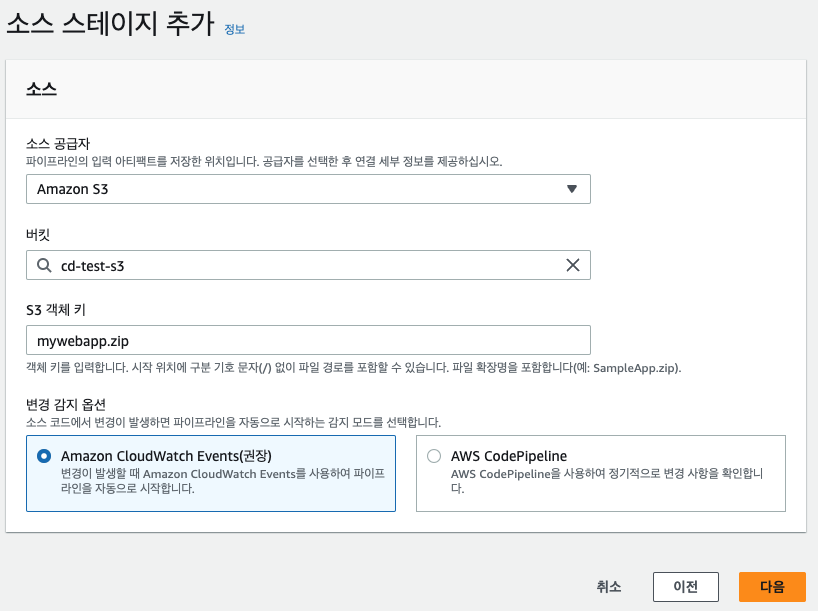
다음 빌드 공급자 화면은 실습에서 빌드를 할 일이 없기 때문에 건너뛴다.
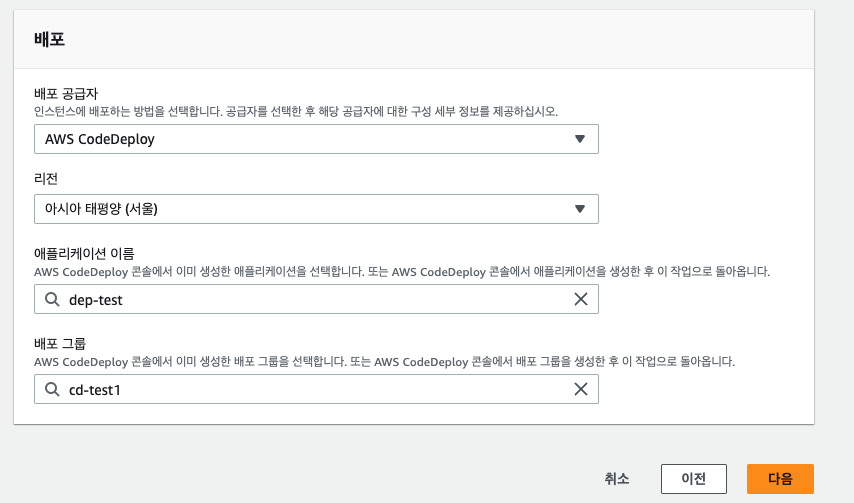
배포 스테이지는 AWS CodeDeploy, 리전을 서울로 선택하고 애플리케이션 이름과 배포 그룹은 앞서 실습한 내용이 있어서 바로 드롭다운으로 선택할 수 있다.
교재 내용대로 파이프라인 구성 실패가 떴다. 코드 파이프라인에서는 버킷의 객체의 버전을 기반으로 관리하기 때문에, S3 버킷의 버전 관리 옵션이 켜져있지 않으면 이렇게 에러가 뜬다고 한다. S3에 접속하여 버킷 버전 관리 옵션을 켜준다.
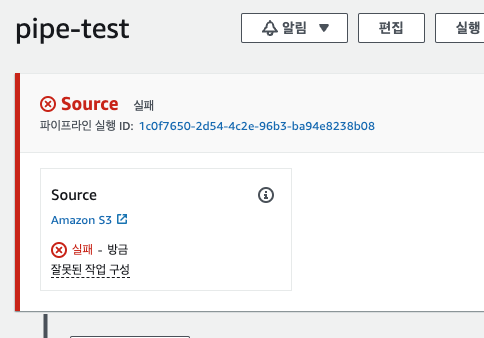
이후 재시도 버튼을 누르면 파이프라인 구성에 성공하는 것을 확인할 수 있다.
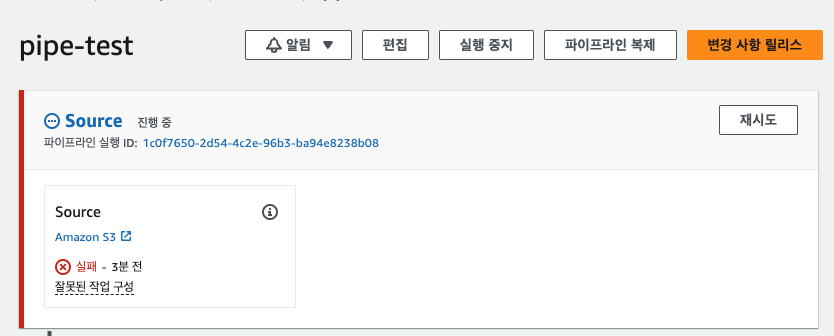
마지막으로 구성된 파이프라인에서 index.html 파일을 업데이트하면 파이프라인이 돌아서 배포가 자동으로 이루어지는지 확인해본다. 자동으로 파이프라인이 돌아서 배포가 이루어졌다.

'Bravo My Life > Books' 카테고리의 다른 글
| 업무에 바로쓰는 aws입문: 1. IAM, EC2, RDS, S3, CloudWatch, Lambda (0) | 2023.09.09 |
|---|---|
| [작성중] 파이썬 알고리즘 인터뷰ㅡ박상길, 정진호 (0) | 2023.07.26 |
| 피타고라스 생각 수업 ㅡ 이광연, 유노라이프 (0) | 2023.06.17 |
| 프로젝트 헤일메리 - 앤디 위어 / 알에이치코리아 (0) | 2023.06.10 |
| 해부학-사카이 다쓰오, 윤관현, 이영란-성안당 (3) | 2023.06.03 |



{kind=link}